Vibe Coding for Marketers: A Beginner’s Guide
You’ve heard “learn to build”, “ship your own tools”, “automate your busywork”, but nobody explains where to start.
Canva made this painfully clear: they gave 5,000 employees a full week to explore AI, and most couldn’t figure out how to start. No surprise there, most vibe-coding tools expect you to manage files, wrangle a terminal, and deploy to a server just like a developer would.
Good news, you don’t need any of this to build your own marketing tools and workflows.
I’ll walk you through the exact setup I use. It runs via Letaido in the browser, so you don’t need to install anything, manage files, or leave your laptop running overnight.
Recommendation
🔮 Letaido is an AI workspace that lives in your browser. It writes the code, stores the data, hosts the tools, and runs your automations on a schedule.
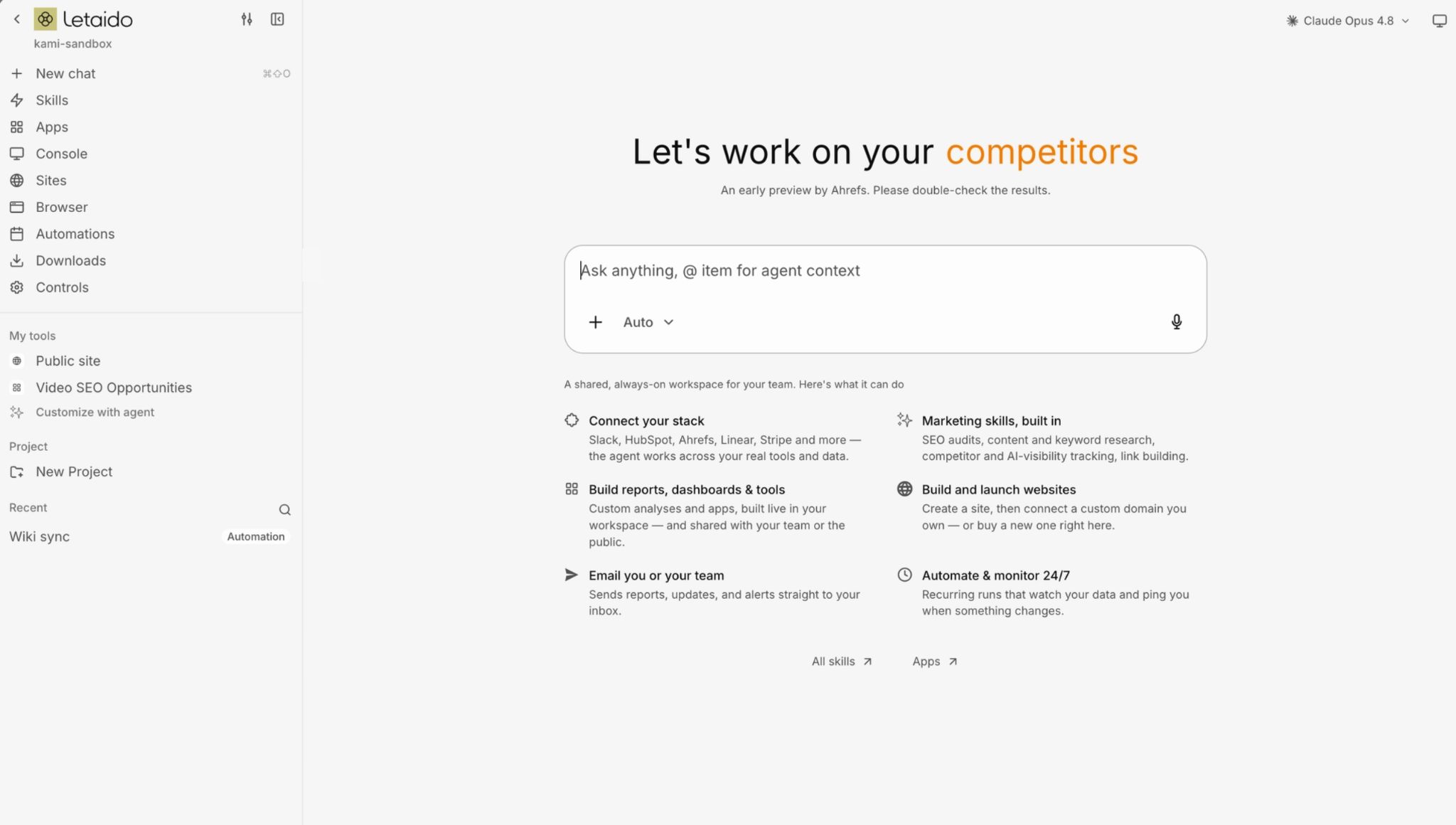
Vibe coding lets you build the reporting dashboards, competitor monitors, keyword-clustering tools, and content workflows you’d normally wait on a dev team (or a budget) for. You describe the workflow the way you’d explain it to a new hire, and the AI builds it.
Letaido is the AI marketing platform made for the job. You point it at your tools and data, describe the report or workflow you want, and it builds and runs it in the cloud for you.
You have two ways to create your builds.
There’s a private Console only your team can see (like internal tools and dashboards):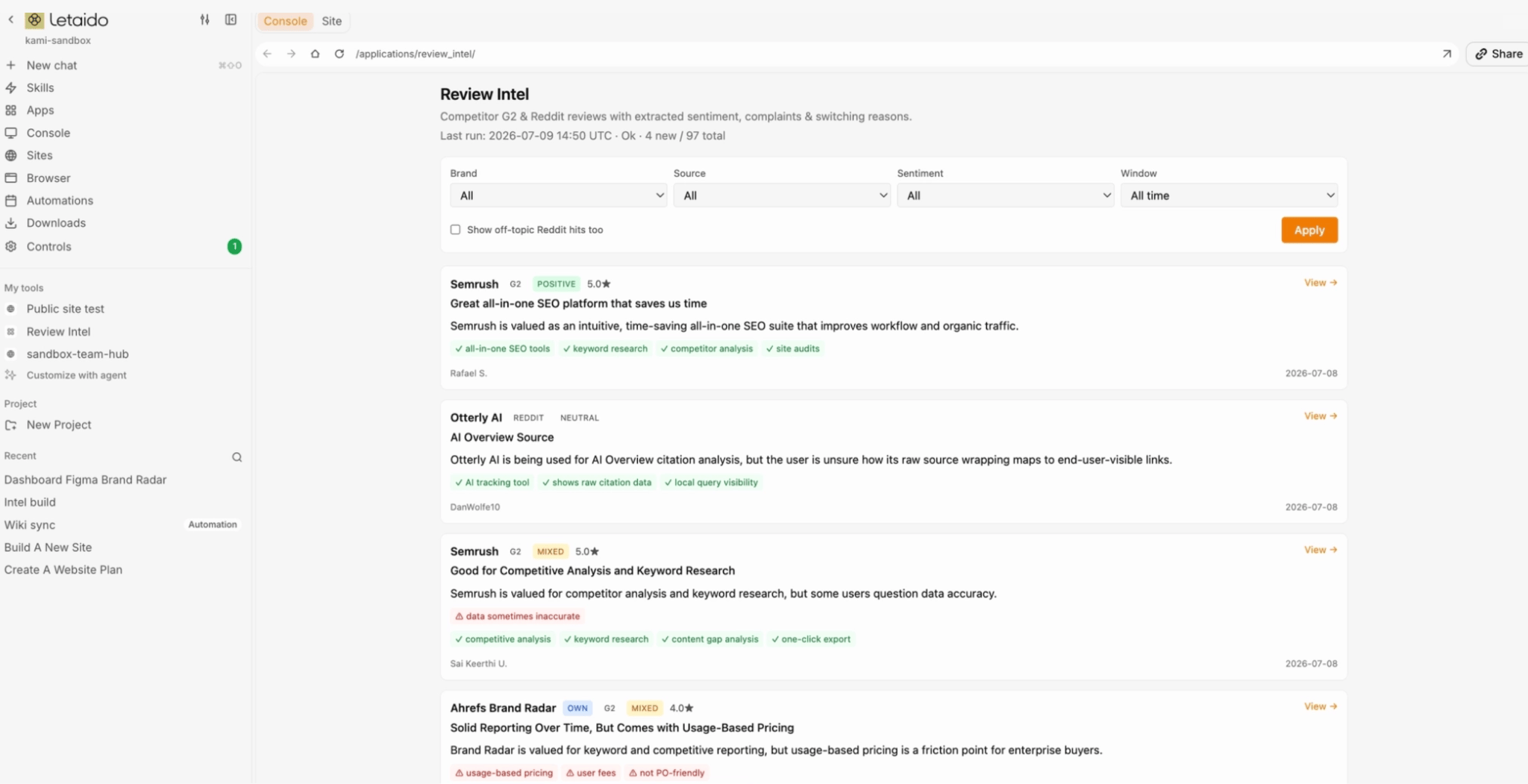
There’s also a public site (for pages you want to publicly share):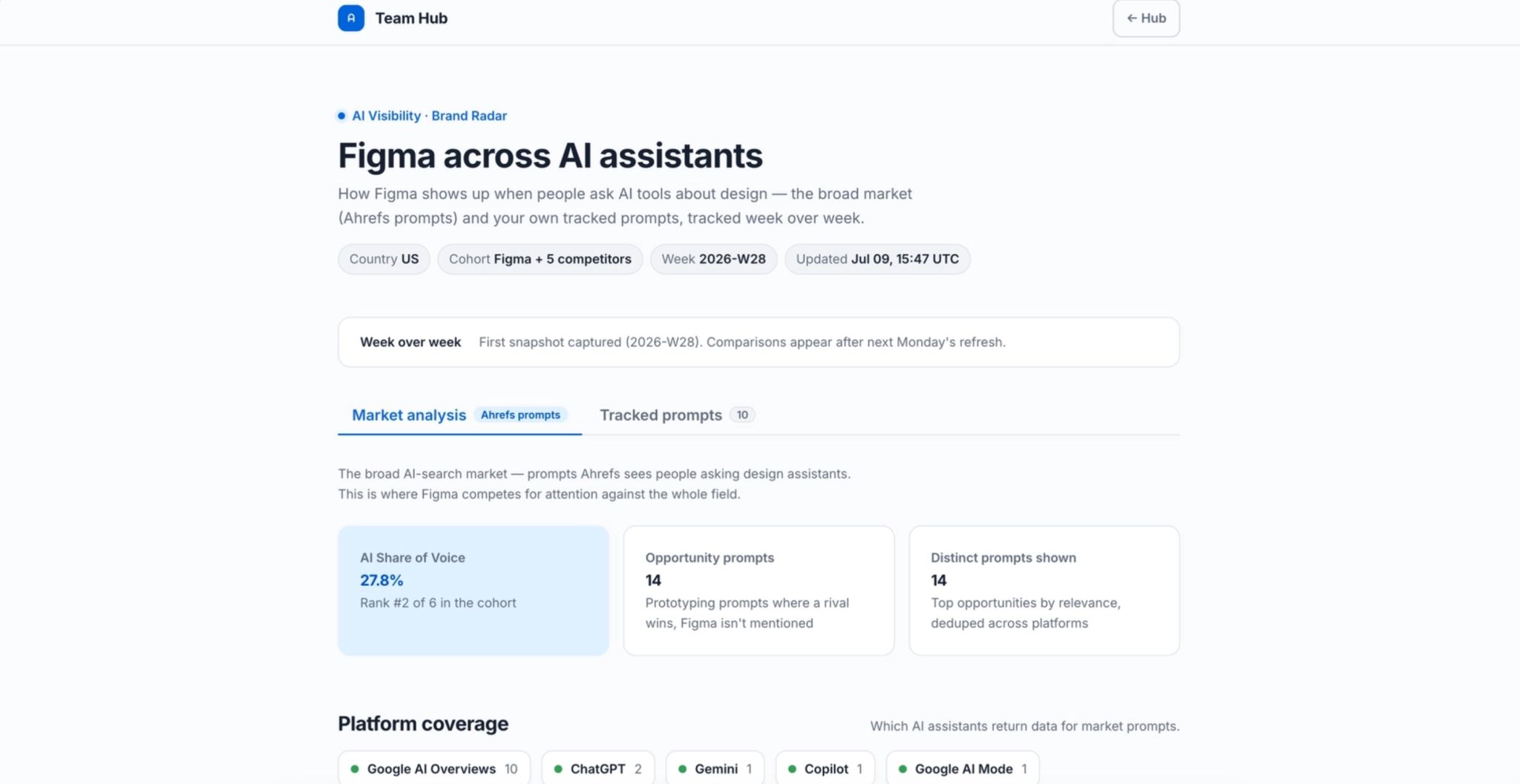
A few things worth knowing up front:
All models in one place. You can switch between Claude, GPT, Gemini, and others from a dropdown, per task. No need for separate subscriptions or API keys. 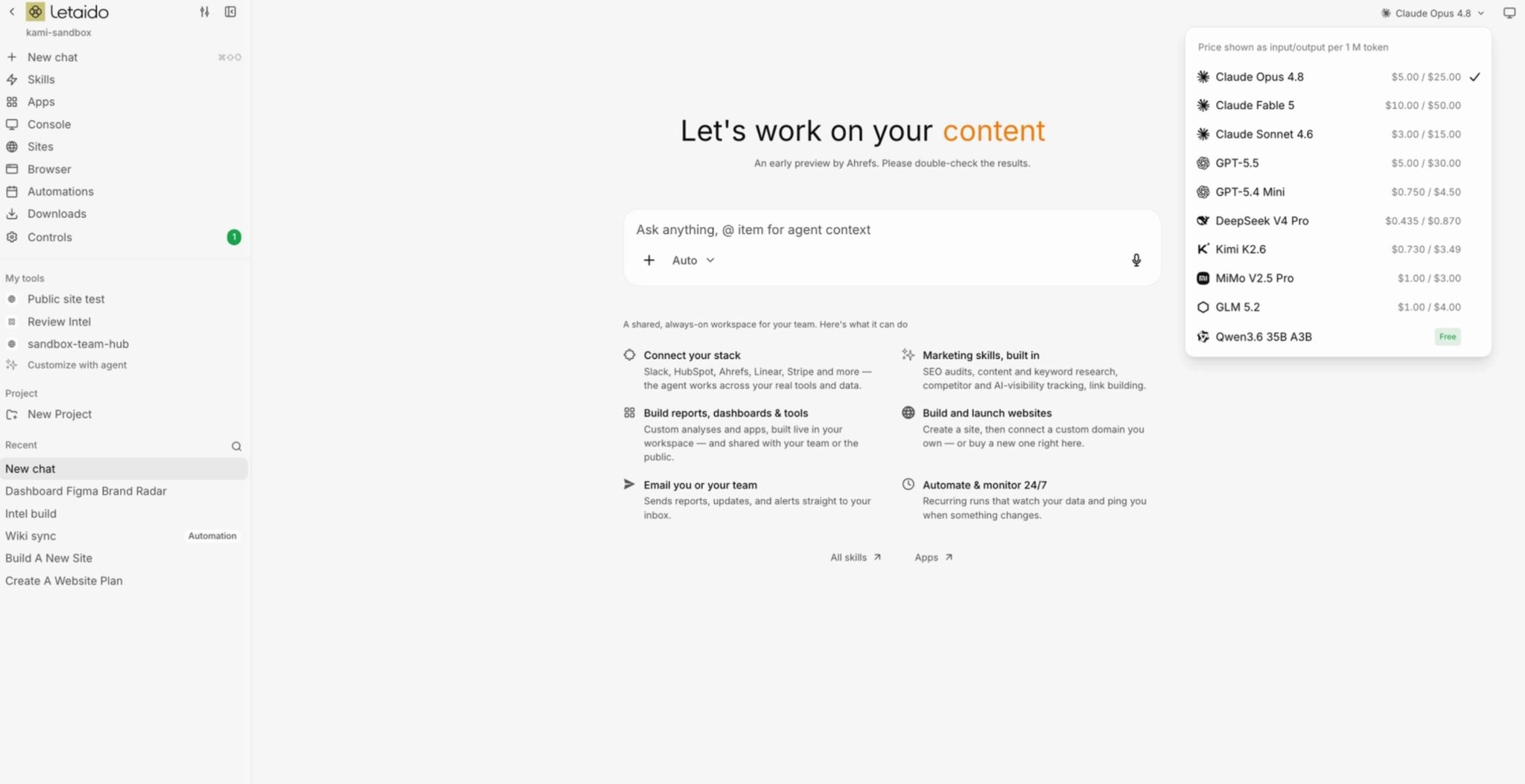
Native connectors. 35+ marketing tools like Slack, HubSpot, Notion, GitHub, Linear, Mailchimp, Stripe, WordPress, or Airtable already connected. 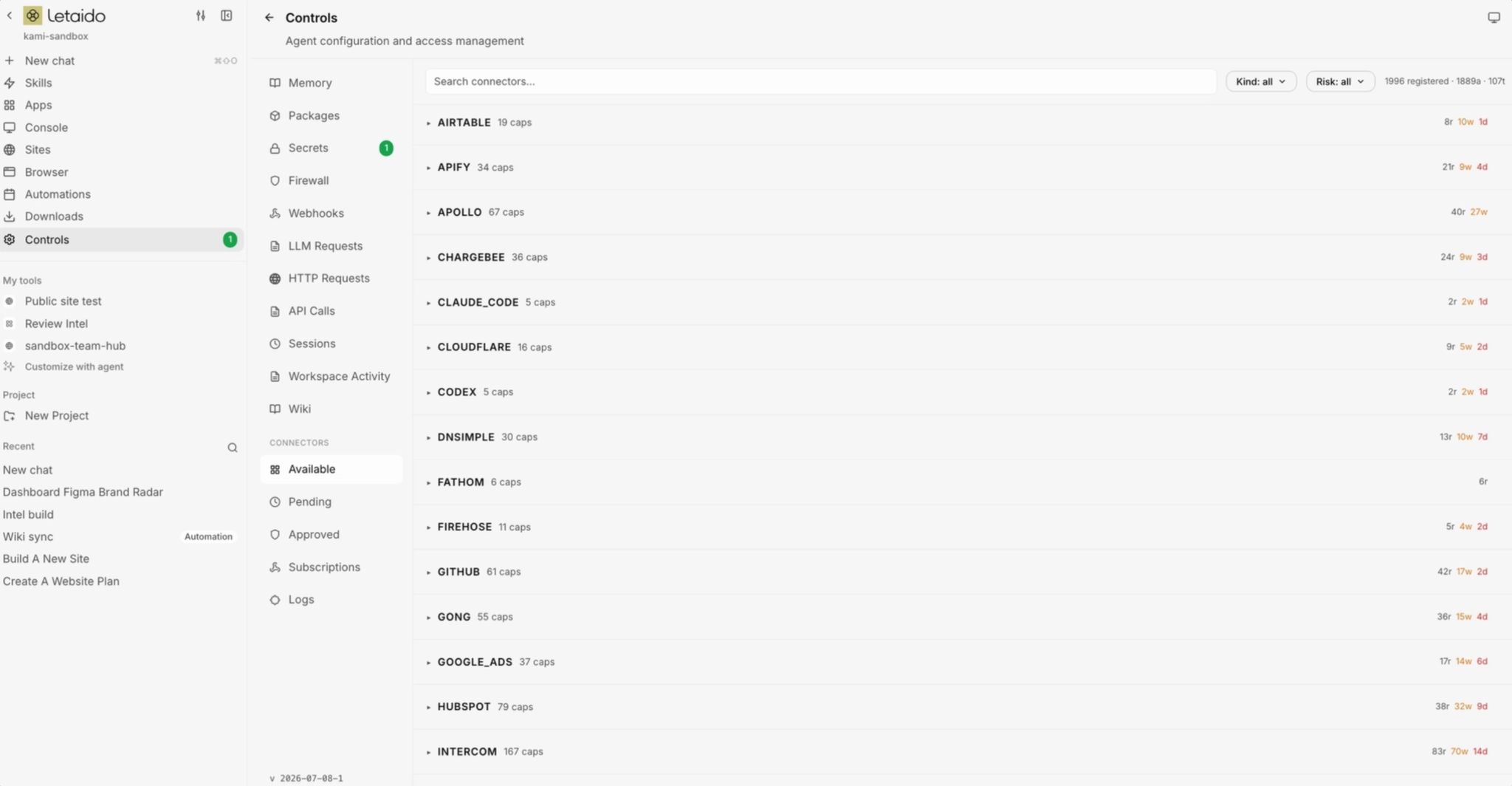
Pre-built marketing skills. An Ahrefs-maintained library of skills, a set of steps for your AI agent to follow, based on real best practices, so you’re not starting from a blank prompt. 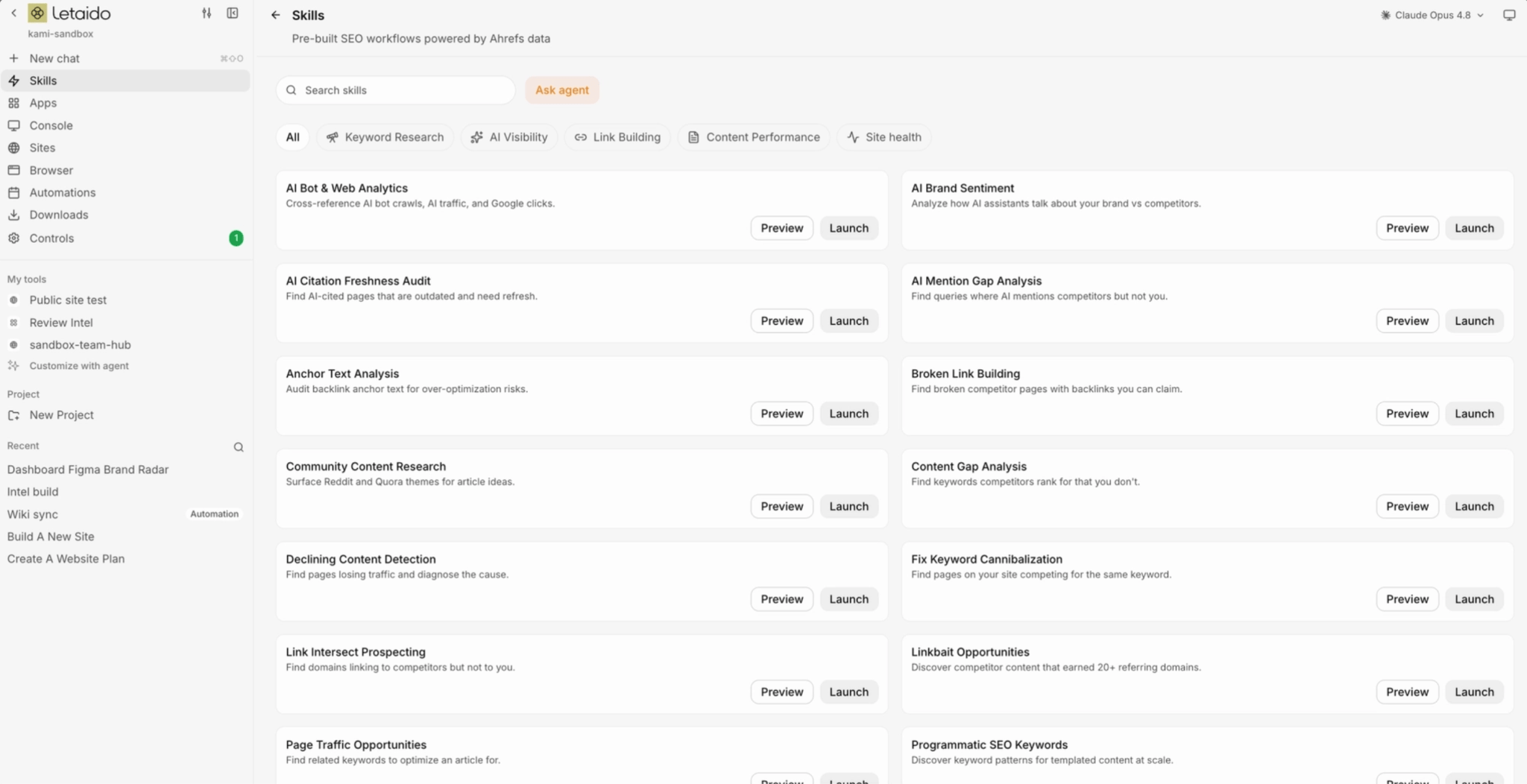
Built for teams. Whatever one person sets up (skills, connectors, memory, apps) is there for everyone, so the team compounds each other’s work instead of rebuilding it. Seats are free (the $99/month is per workspace, not per person), so you can invite everyone, and roles keep it safe: members can chat and build, owners and admins approve new connectors or handle secrets. 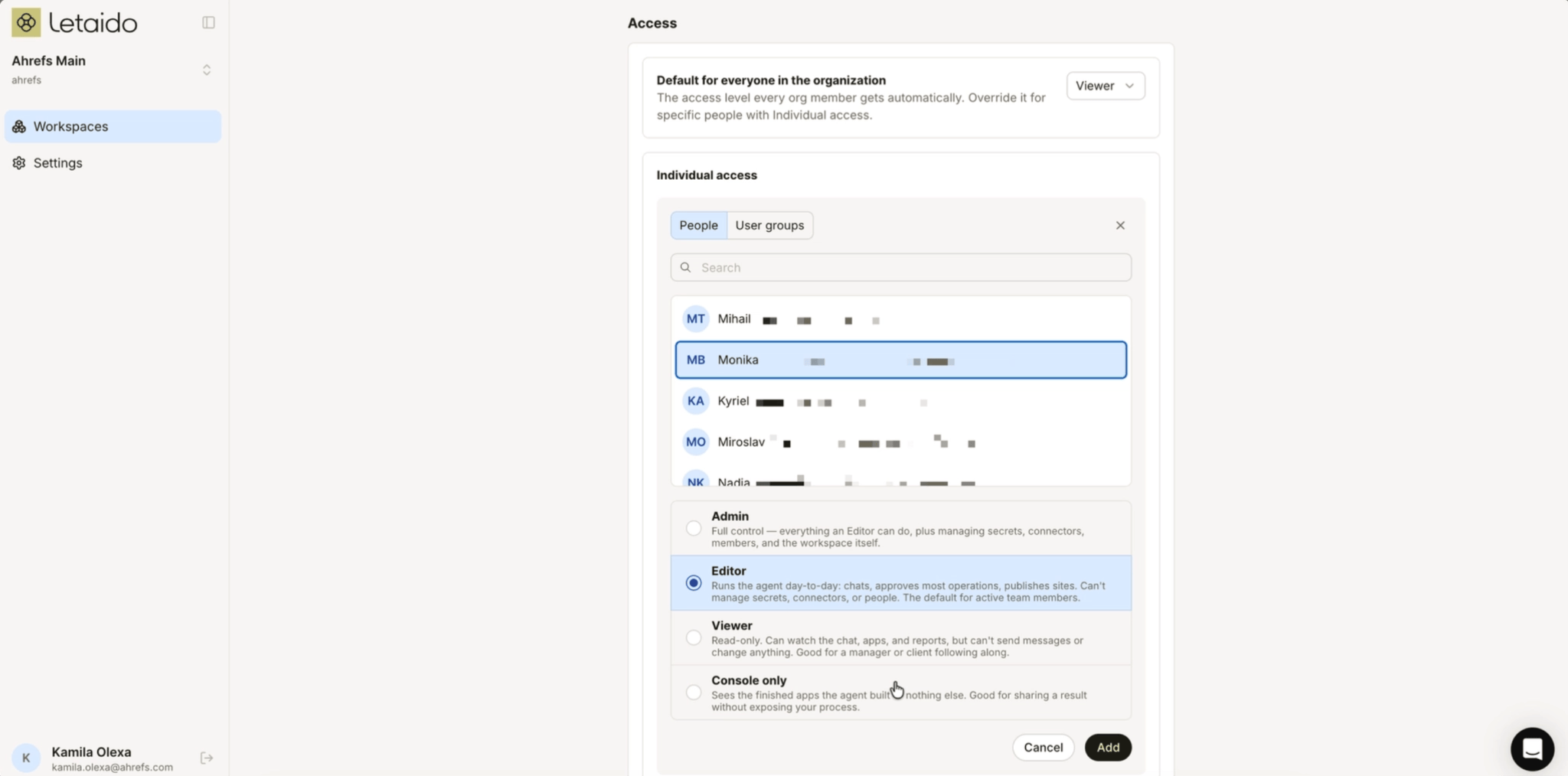
Share outside the team. For a one-off like a client report, ask the agent to create a guest link for your app or report, and it creates a public site with a default Letaido domain. You can also change the domain to one you already own, or buy a new one inside Letaido, and it will sort out the security certificate for you as well. 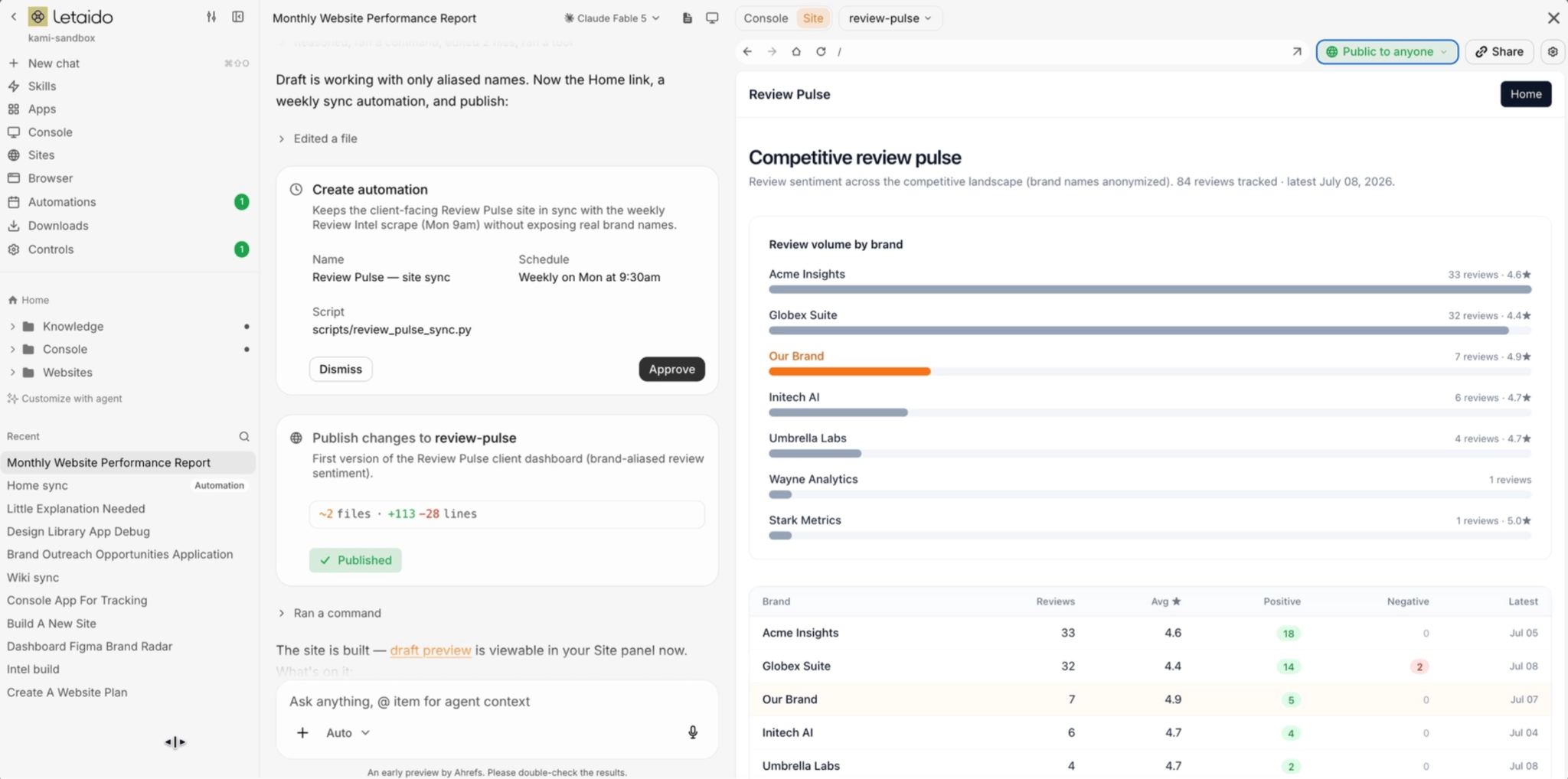
Hosting and secrets are handled for you. This removes the two biggest beginner risks: exposed API keys pushed to GitHub and accidental public reports. You only need to think of where to publish your workflows – internal data belongs in the Console, while the public site is a URL anyone can find and Google can index, so double-check before it goes live.
Recommendation
⚠️ If you want to follow along with me, you’ll need Ahrefs. The $99/month covers the Letaido platform and your AI credits, but the agent reads your Ahrefs project data through your existing Ahrefs plan, so an active account is required, and your data limits (tracked keywords, projects, etc.) follow whatever plan you’re on.
- Sign up at letaido.com – hit “Get started” and create an account.
- Name your organization – the subdomain you pick becomes the URL where your workspace lives.
- Invite your team – seats are unlimited and free
That’s it. No editor, no Git, no keys to paste.
Choose an AI model and mode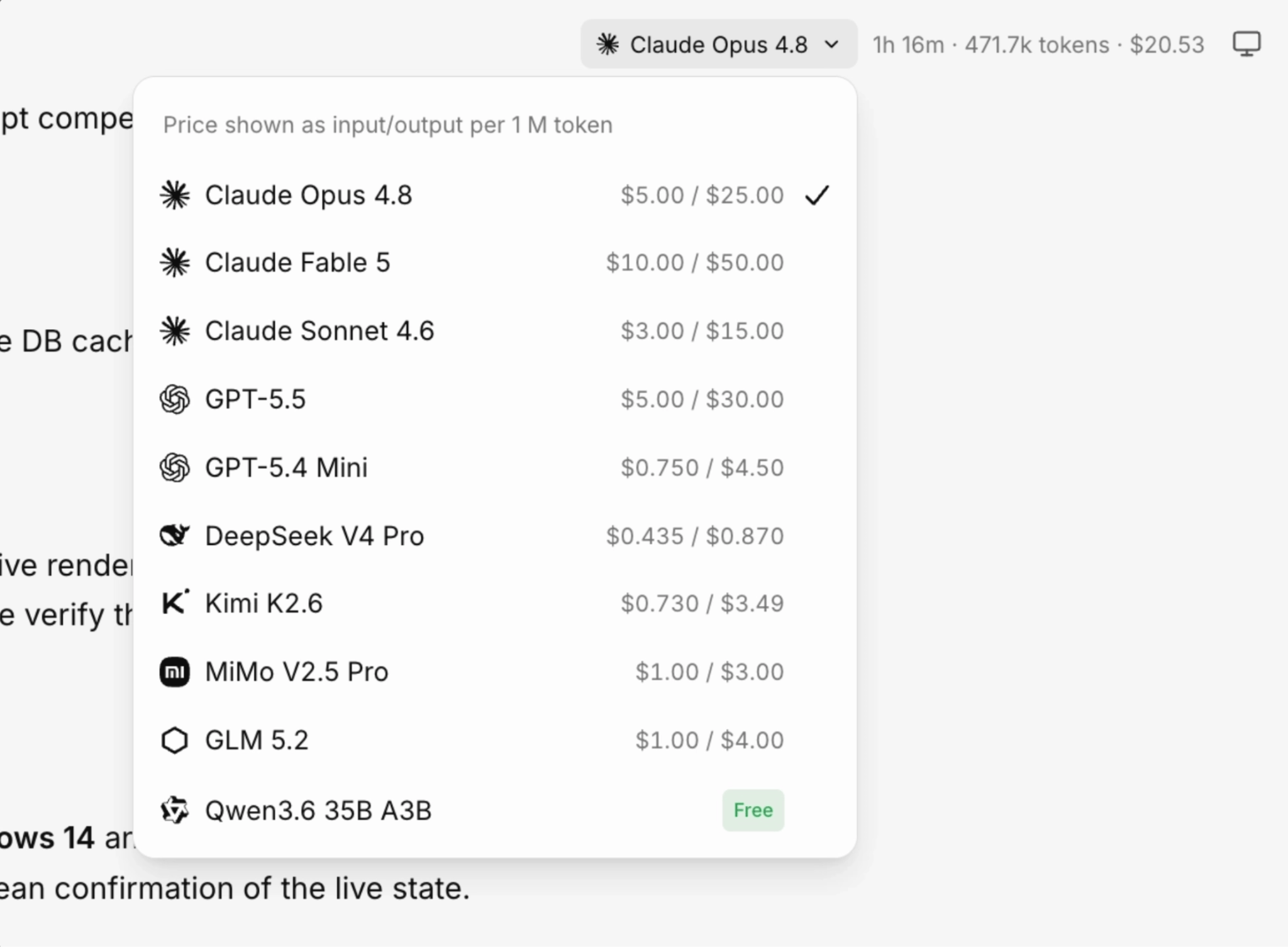
What’s great about Letaido is that you’re not locked into a single model. Your subscription includes $50 in AI credits, so you can switch models freely to match whatever the task calls for.
On the model itself, three factors matter, and they shift constantly as providers ship new versions: quality, speed, and price. Artificial Analysis plots all three across 500+ models if you want the live picture.
If you still worry about spending your $50 AI credits, let me give you an example with different types of AI models.
Let’s say you ask Letaido to look at your Ahrefs project, find keywords your top 3 competitors rank for that you don’t, cluster them by topic, and hand you a prioritized list of content ideas with target keyword, volume, difficulty, and a one-line angle for each, the spend can look like this: 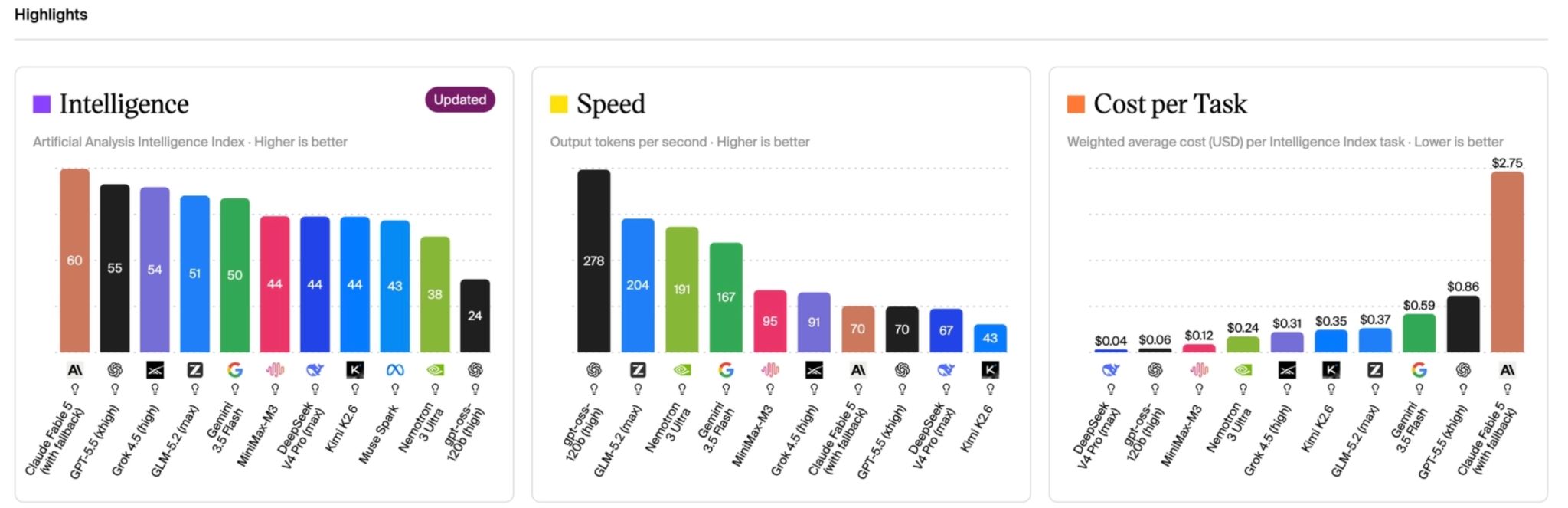
| Model | Tier | Cost per run | $50/month | When you’d pick it |
|---|---|---|---|---|
| GPT-5.4-mini | Cheap workhorse | 3¢ | ~1,600 runs | Fast, high-volume, simple reasoning |
| Claude Sonnet 4.6 | All-rounder | 24¢ | ~200 runs | Sharper clustering + more logical reasoning |
| Claude Fable 5 | Top-tier | 38¢ | ~130 runs | Highest-stakes strategic calls and proposals |
My default is Claude for anything where I describe intent loosely and want it to figure out the shape. I switch to a cheaper model for high-volume, mechanical work (reformatting, batch variations) to keep credit burn down.
Right next to it is a mode selector, which defines the build mode the agent adopts: 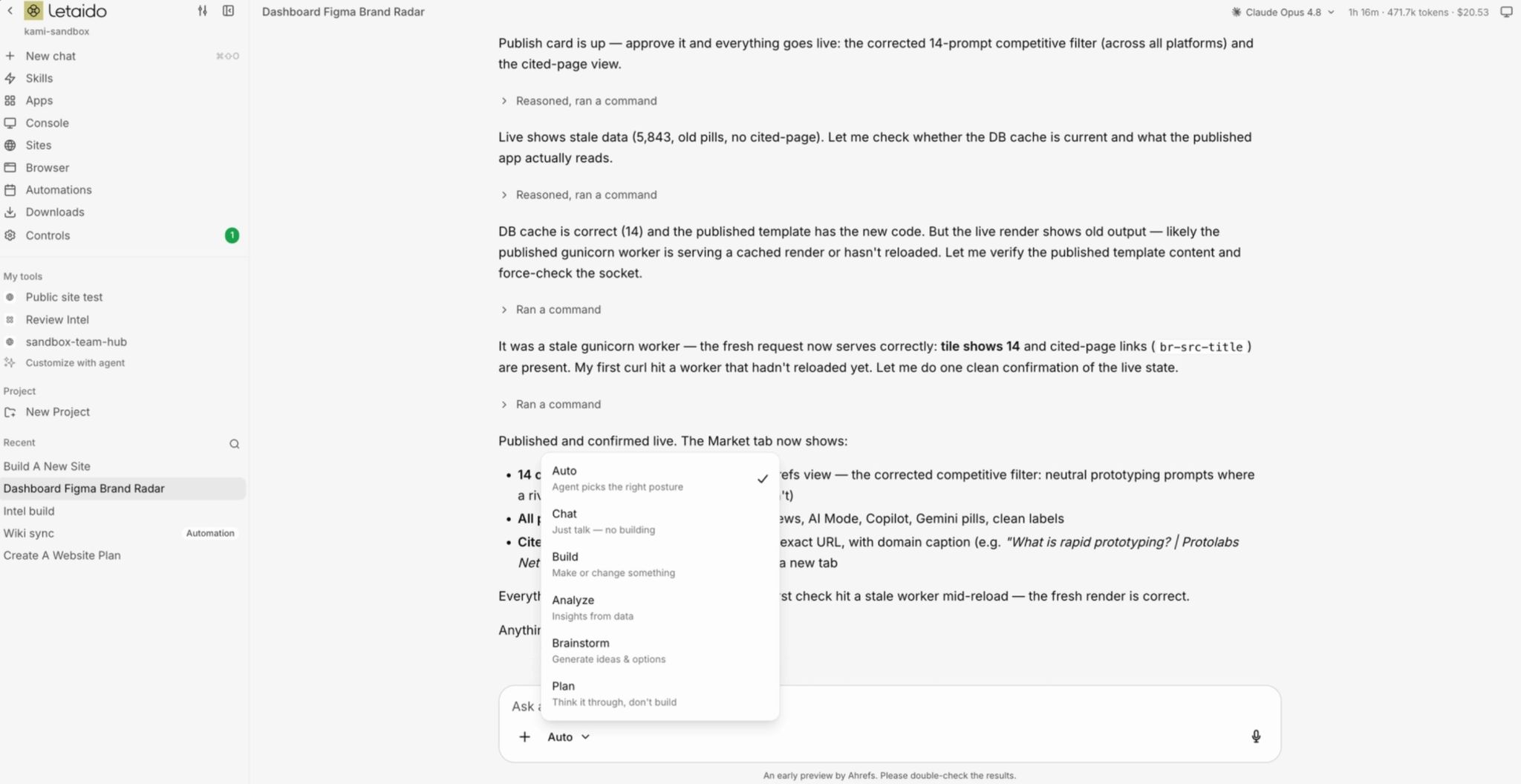
- Chat — talk it through. It answers and discusses, but won’t start building.
- Build — make or change something. It plans, then ships.
- Analyze — crunch data for insight, not to build new software.
- Plan — figure out what and how before doing it.
- Brainstorm — generate options and directions, no committing yet.
- Auto — it reads your intent and picks the right posture itself.
Auto is a fine default. For instance, if you’re in Chat mode and you want something built, it’ll offer you to switch.
Recommendation
💡What burns credits fast is running the heaviest model on light work, and dragging one giant chat across unrelated tasks. Start a fresh chat when a task is done (your memory persists, so you don’t lose context), and let cheaper models, like GPT-5.4 Mini, handle the grunt work.
Create a knowledge base
The context you write yourself beats any external source, because it holds details no model was trained on: your real features, positioning, and voice. Letaido gives you a few ways to store information about your company, so you’re not re-explaining it every chat:
- Memory. The agent reads ~/workspace/.memory.md at the start of every chat using a few tokens. I recommend adding only essential info the agent uses every run (e.g. recurring vocabulary or stylistic rules). Too much information stored = more tokens spent, keep it brief.
- A shared team wiki. Letaido keeps a workspace knowledge base where you can store loads of files you can refer the model to (decisions, competitor files, design files, specific projects, etc.).
| Category | Memory (.memory.md) | Team Wiki (wiki/) |
|---|---|---|
| What it is | Essential notes file | Workspace knowledge base |
| When Letaido reads it | Start of every chat (automatically) | Only for specific tasks |
| Token cost | Every session (scales with size) | Only when a page is read |
| Keep it | Short | Can be large |
| Best for | Recurring vocabulary; Stylistic/voice rules; A pointer to the wiki | Strategy docs; ICPs; Competitors; Product FAQ |
| Rule of thumb | Only what Letaido needs every time | What Letaido needs occasionally / in depth |
| Find it | controls -> memory | controls -> wiki |
Create skills, apps, reports, artifacts, or automations
Five words you’ll see everywhere in Letaido. It’s important to distinguish between them, as building the wrong type can influence the agent’s behavior and reusability.
A skill
A skill is a reusable set of steps, an output format, and rules that the agent reads on demand whenever a request you say in plain language matches. The fastest way to start is to clone one from the Ahrefs library and customize it. 
You can also create your own via chat.
- Give the skill a name that will trigger it
- Describe the rules it should follow
- Reference the examples if necessary
An app
An app is an interactive tool the agent builds. It can read your databases, call your connectors, and show results. 
A monthly report you configure and check in the console is an app, so is a writing workflow that takes a keyword and hands back a draft. 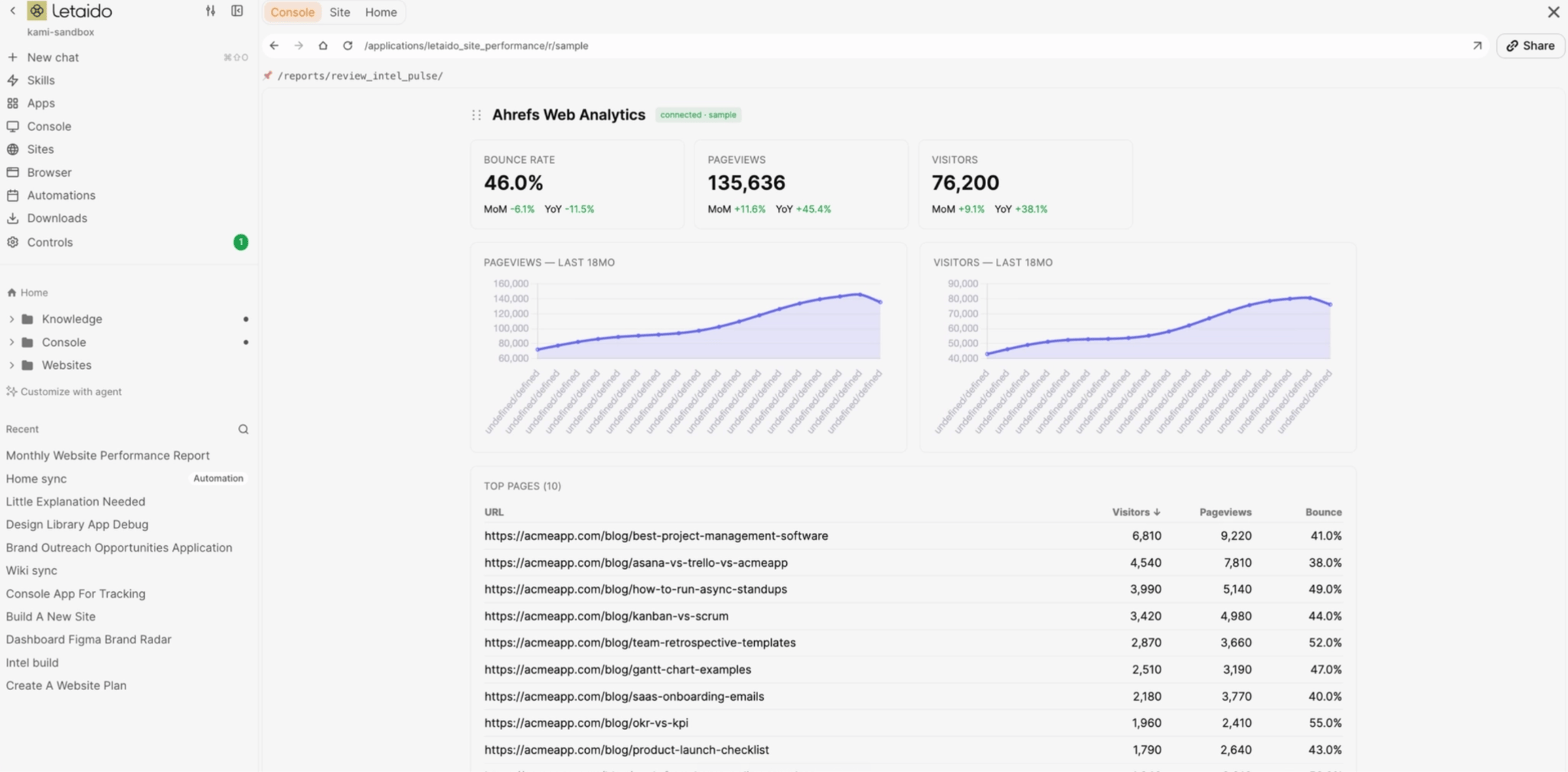
The moment you create, edit, or trigger things inside it, it’s an app.
A report
A report is a live, read-only view of your data. The agent builds it once, and every time you open it, it pulls fresh numbers and lays them out for you. 
A sentiment overview that’s current whenever you look, a lead-quality breakdown pulled straight from your CRM, these are reports. You don’t configure or manage anything inside them, you just read. 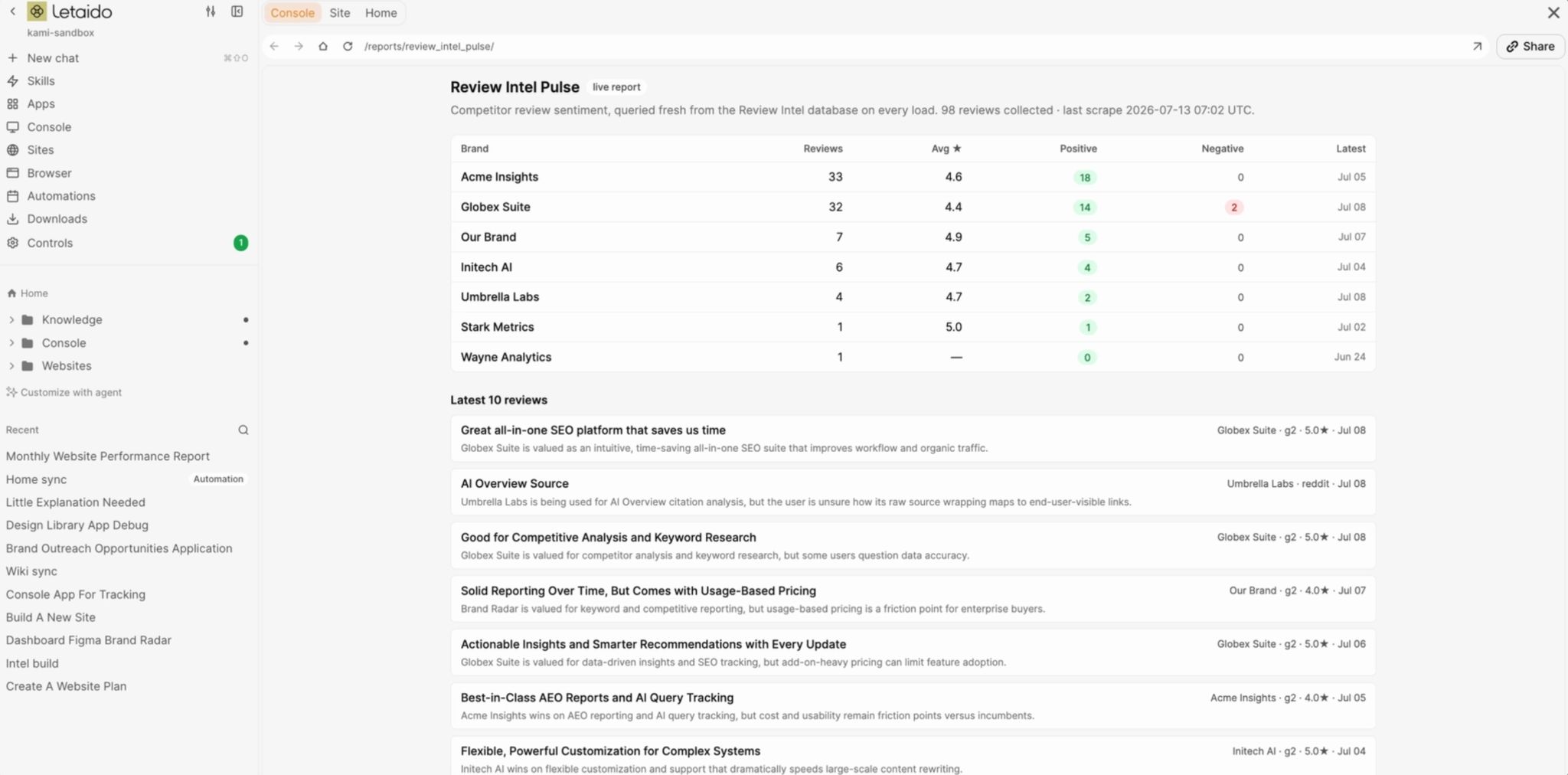
An artifact
An artifact is a frozen output, something the agent produced once that doesn’t change afterward. 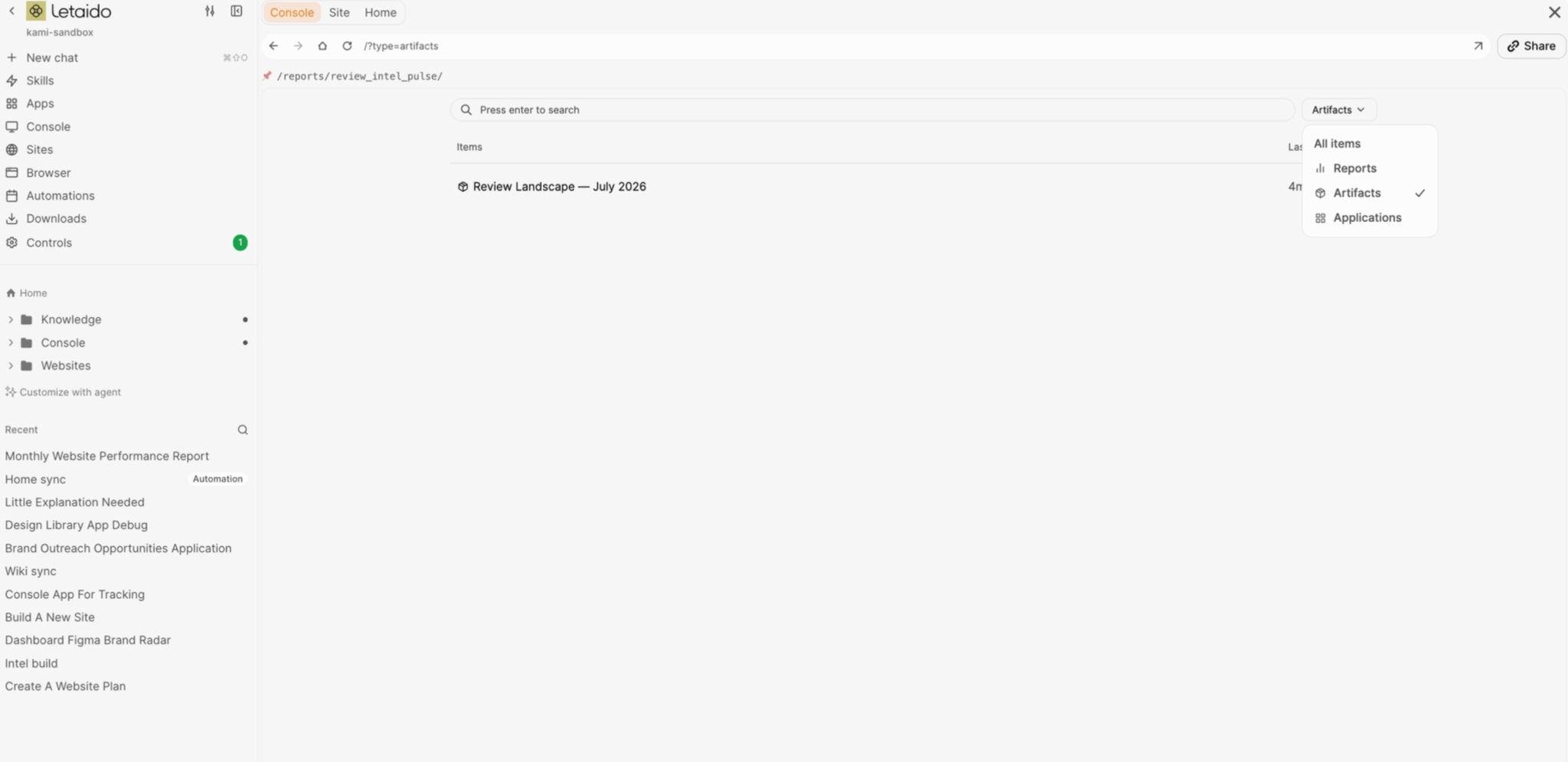
A chart from last month’s competitor G2 reviews, a one-off visualization. They’re snapshots: perfect for “here’s what we found”. 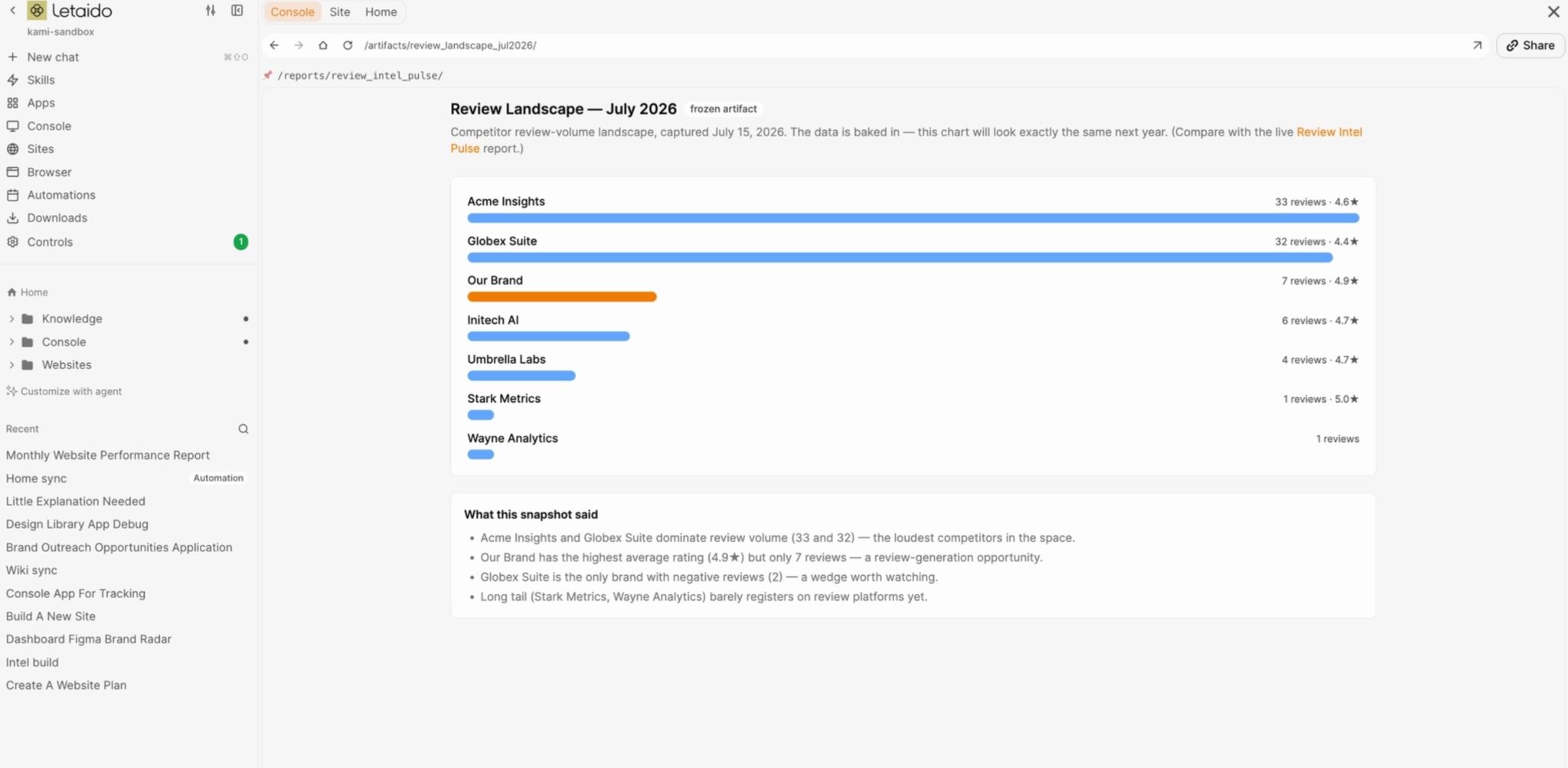
Recommendation
🔮 Apps, reports, and artifacts can live in your Console and be shared with your team only, or be published to your public site for anyone with a link to use.
An automation
Automation is a task that runs on its own, at a specific time, without you triggering it. There are two ways to create it:
With an agent – you describe what you want done and when, the agent writes it, and runs it from then on: 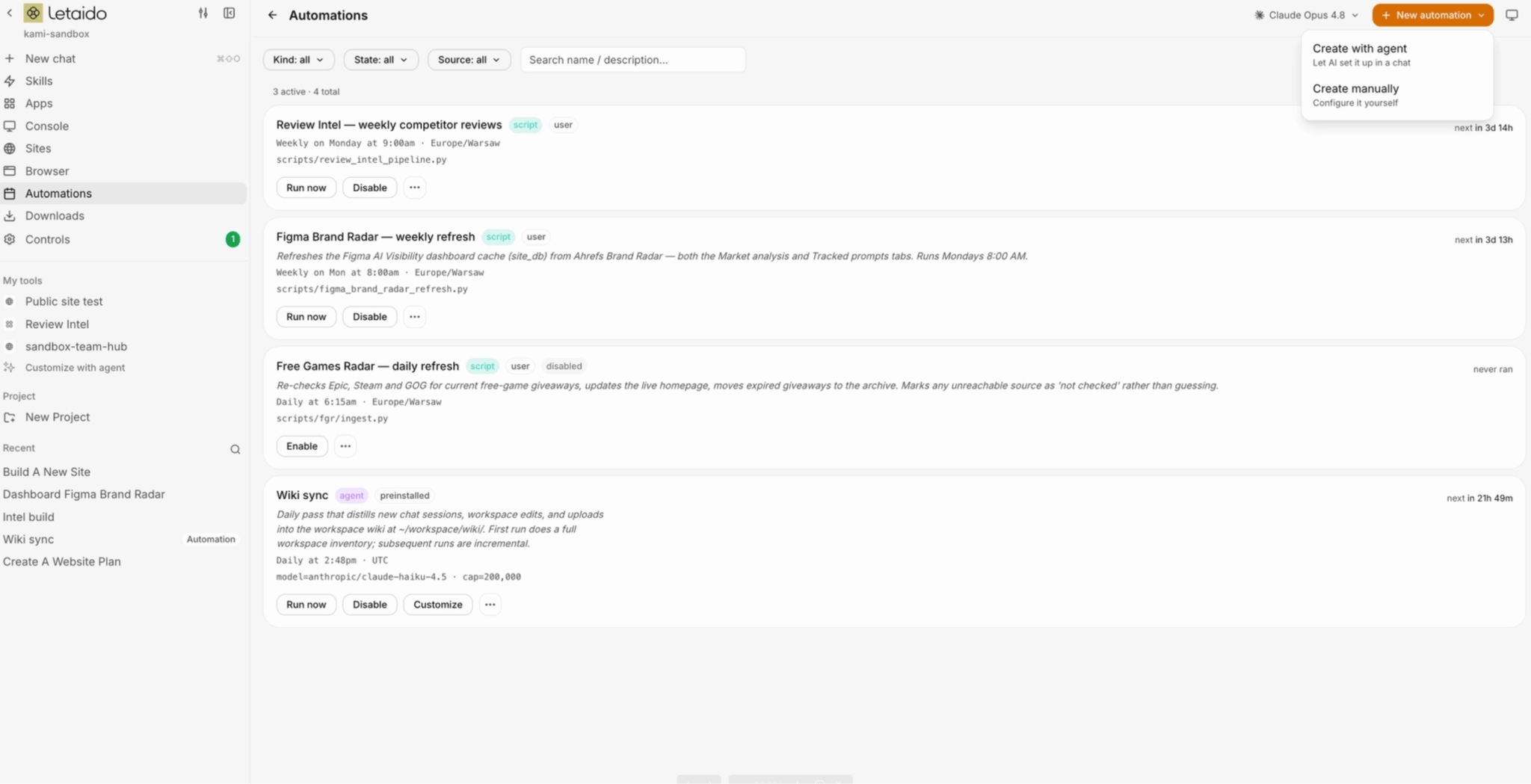
Or manually – automate an agent or a simple script to run with a set of limitations (schedule, max tokens used, etc.): 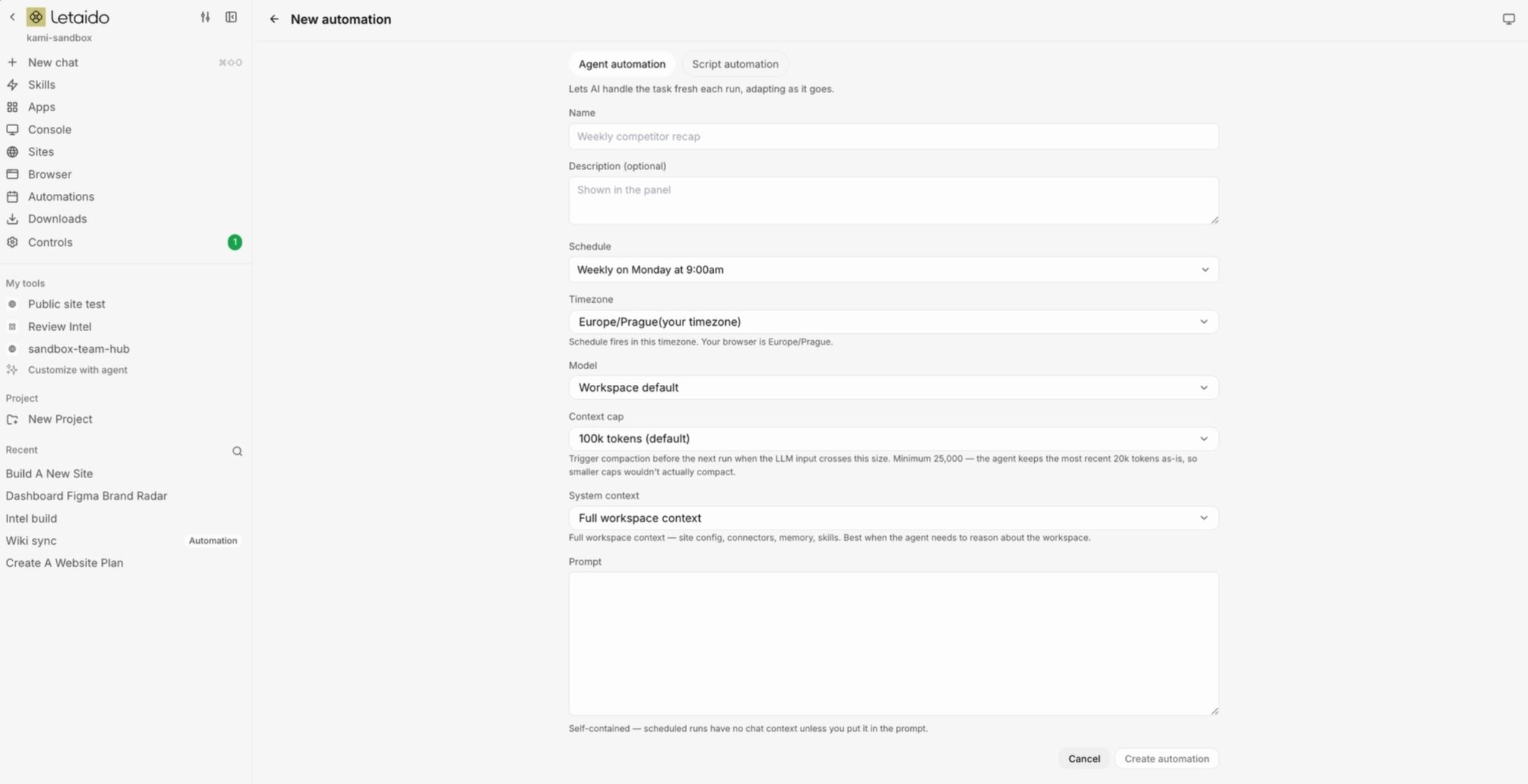
Recommendation
💡 Rule of thumb: package know-how you’d otherwise re-explain as a skill, build the thing you click into as an app, and put an automation on top when it should run without you. A single build can use all three, such as an automation that runs a skill on a schedule and writes the result into an app.
Add integrations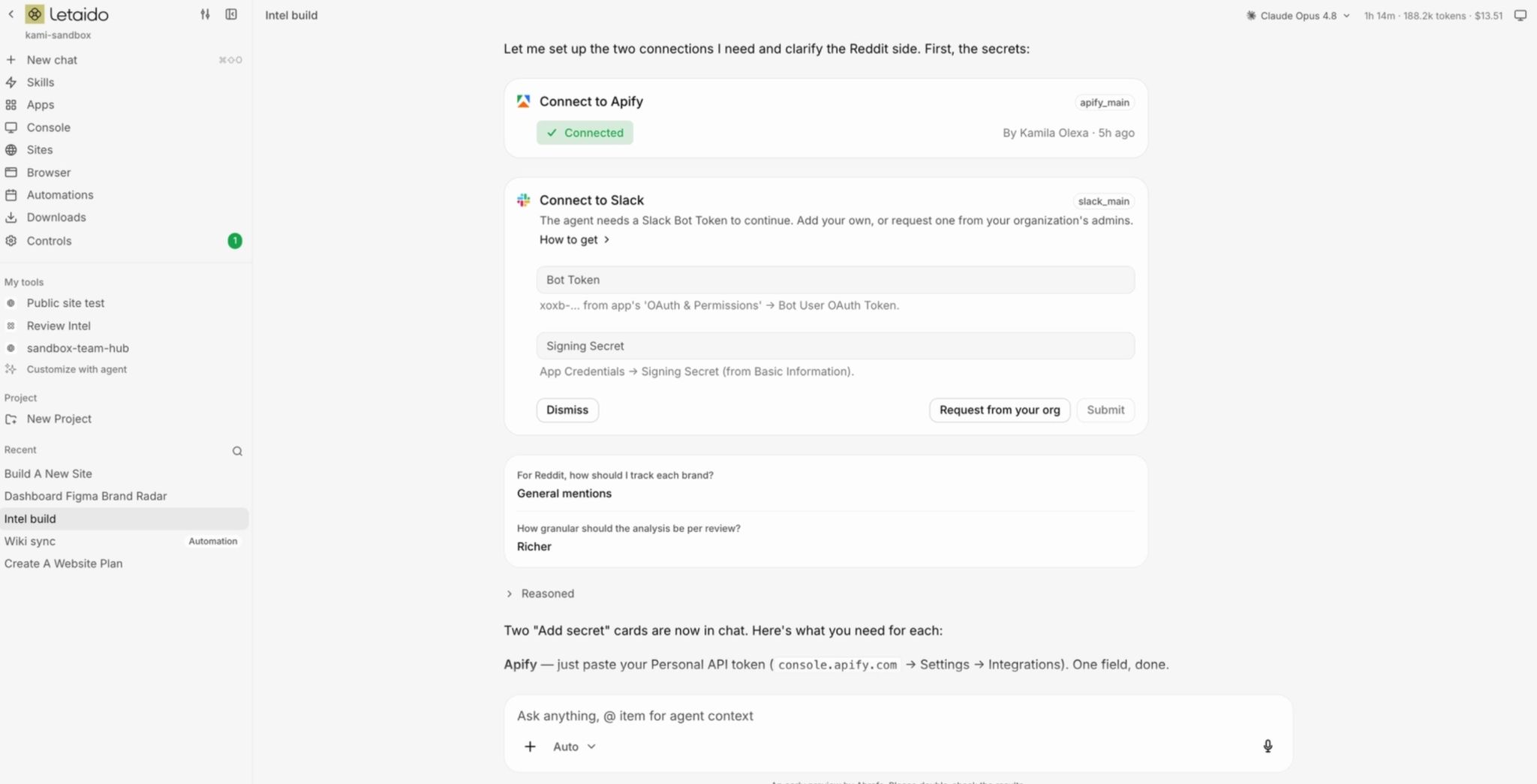
If you want to pull your HubSpot data, scrape social media with Apify, or use other external tools, the agent needs to use the connectors to handle the endpoints, parameters, and the authentication behind the scenes. For instance, you connect HubSpot once, and every time you say “pull this week’s deals from HubSpot”, the agent knows exactly what to do.
Connectors can read, but also take action via your tools – post a summary to Slack, publish a post to WordPress, open a Linear ticket, update a HubSpot deal, or send an email.
There are tons of common tools like Stripe, Fathom, or Mailchimp available – a full list of connectors can be found here.
To add access to your connector:
- Tell the agent via chat you want to add the specific connector
- Get the API keys (click “How to get” in the card if you need help locating it)
- Paste the keys and click “Submit”
- Your connector is added under “Controls” → “Approved”, you can revoke it at any time
Every good build comes down to the same four moves: write the prompt, point it at your data, share it with the team, and start with one workflow you already know.
Writing the prompt
Unlike a one-off chat message, this is the instruction the agent will execute again and again, which means anything vague or missing gets repeated on every run. Three things do most of the work:
- What output you want. Describe the finished thing. A Slack message, a table, a summary as concretely as you can.
- Where the data comes from. Name the exact source the agent should pull from, whether that’s a connector, a file, or a page to scrape, so it never has to guess.
- What the instructions and limiters are. Spell out the steps it should follow and, just as importantly, the boundaries it shouldn’t cross. What it should compare, ignore, and leave untouched.
A few examples: 
- Output = Slack updates about new and lost deals every week.
- Data = HubSpot deals (native connector).
- Instruction = compare this week to last, flag new deals vs deals lost, post to #sales-updates.
- Where it lives = runs every Friday at 8am on its own -> a scheduled job in Letaido.
The best practices boil down to:
- Be specific. Vague requests trigger a clarifying questionnaire. Not “help me with onboarding emails” but “draft a 4-email welcome sequence for new signups, one CTA each, under 120 words.”
- Specify the format. “Reply in a table,” “JSON only,” “markdown with headings.” Default outputs are conversational, so saying the shape up front saves edits.
- Say what not to do. “Do not summarize what stayed the same.”, “Reply exactly: No changes detected”.
- Ask for a plan when it’s fuzzy. If a build touches multiple systems or you’re not sure it’s feasible, ask for a plan.
- Feed facts, never recall them. Point it at the connector or file. It should reason over what you give it, never supply your metrics from memory.
Map where your data exists
Before you can build anything, you need to know what data you’re working with and where it lives. Good builds run on real data, and that data is already scattered across the tools you use every day.
1. List every tool, app, and site you touch for work
Your analytics platform, your CRM, your project tracker, the spreadsheets, the dashboards. For each one, write down the specific data points it holds. Don’t stop at “SEO data”; get down to “keyword positions, clicks by page, daily impressions.”
2. Connect it to Letaido
Once you know where your data lives, there are three ways to push it to Letaido:
Connectors – Check whether your tool is already in Letaido’s connectors list, if it is, ask to connect it via + New chat.
API keys – if your tool isn’t in the connectors list. Generate a standard API key from the tool, then ask the agent in the chat to connect it.
Web scrape – for anything on a public page, no login required. Think competitor pricing, review sites, or SERP. 
TLDR
- Sign up for Letaido and connect the one tool your work lives in most.
- Pick the workflow you do most often. For me, reporting was the easiest win because the steps never changed.
- Write it as plain steps, 1 through 5, the way you’d explain it to a new hire.
- Describe it to Letaido one step at a time, and let it build with you.
- Check the output, then put an automation on it.
What to build first
If your head feels fuzzy, get inspired by the builds my colleagues shared for automating SEO, product marketing, or content marketing.
You can run an end-to-end keyword research process – take your primary keywords, sort them into clusters, and create a content brief 
Create a paid ads campaign based on a competitor’s spend – find keywords competitor bids on, fetch and analyze their landing pages, generate creatives and multiple copy variations per ad group. 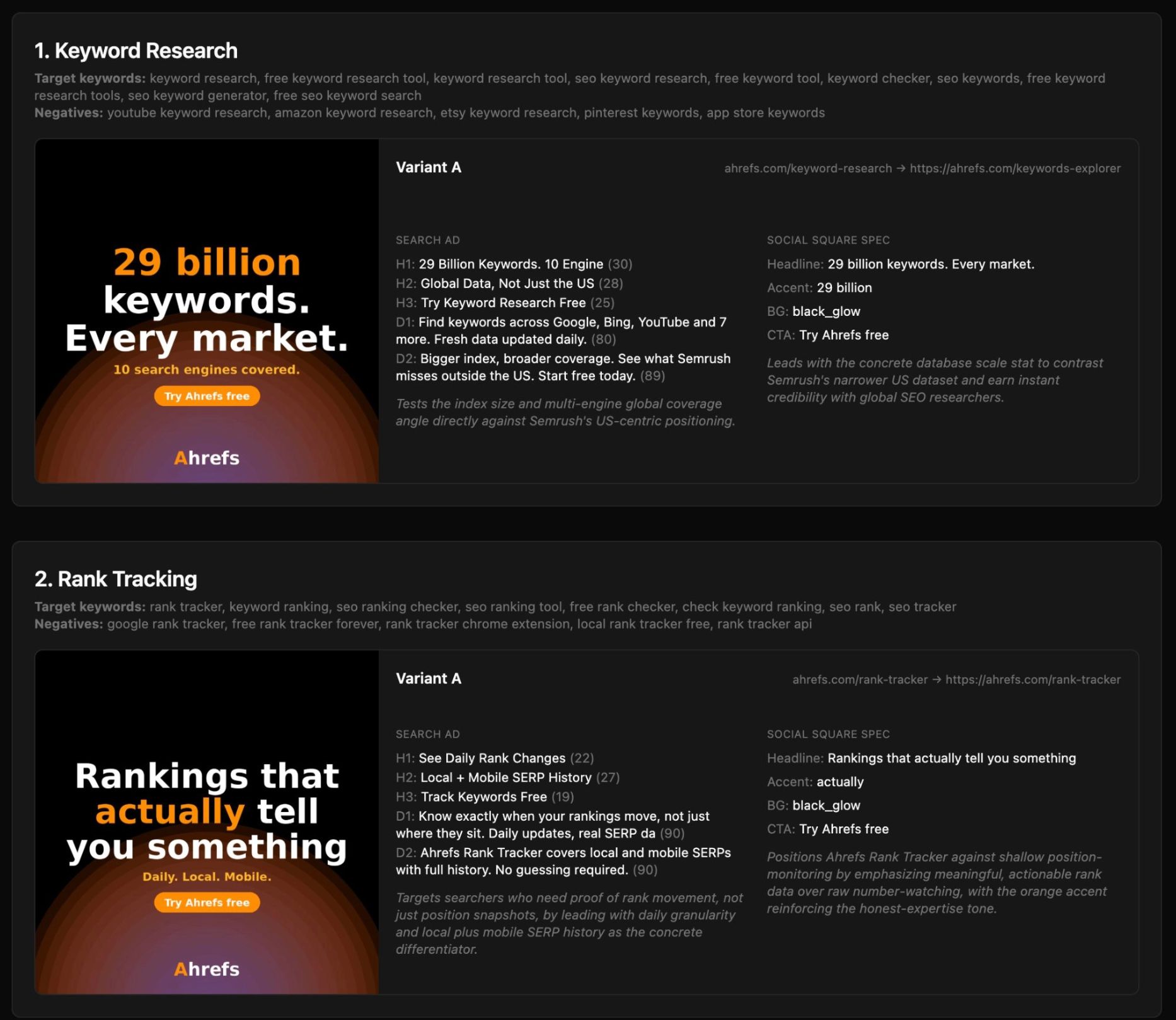
Update old articles and fight traffic decline – the pipeline fetches articles, extracts the page content, then runs diagnostics. 
You do not need a dozen builds. You need one, finished, from your own context.
Reality check
The hype is loud right now. These builds will not replace your strategy, your taste, or your relationships. They will not magically rank you number one. The first version of anything you build will be raw.
However, automating your work will take the repetitive 70% off your plate so you can spend your hours on the fun stuff. The leverage comes from wiring steps together so a workflow you used to do by hand now runs from one command – or, with Letaido, on its own every Monday at 9am.
You know your job better than any tool does. Start there, build one small thing, and iterate it to your quality bar.
When you give it a go, tag/DM me! I’d love to see your builds in action 🙂
Google Doesn’t Punish AI Content; It Punishes Bad Content (331k Pages Studied)
I still have plenty of questions about how Google treats AI-generated content.
On the one hand, Google says they don’t care whether AI is used for content creation, as long as the content isn’t designed “with the primary purpose of manipulating ranking in search results.”
Automation has long been used in publishing to create useful content. AI can assist with and generate useful content in exciting new ways.
On the other hand, people like Lily Ray and Glenn Gabe have shared many examples of so-called “mount AI” traffic graphs: websites that scaled content creation with AI, saw a heroic spike in rankings and traffic… and then watched their organic performance tank a few months after publication.
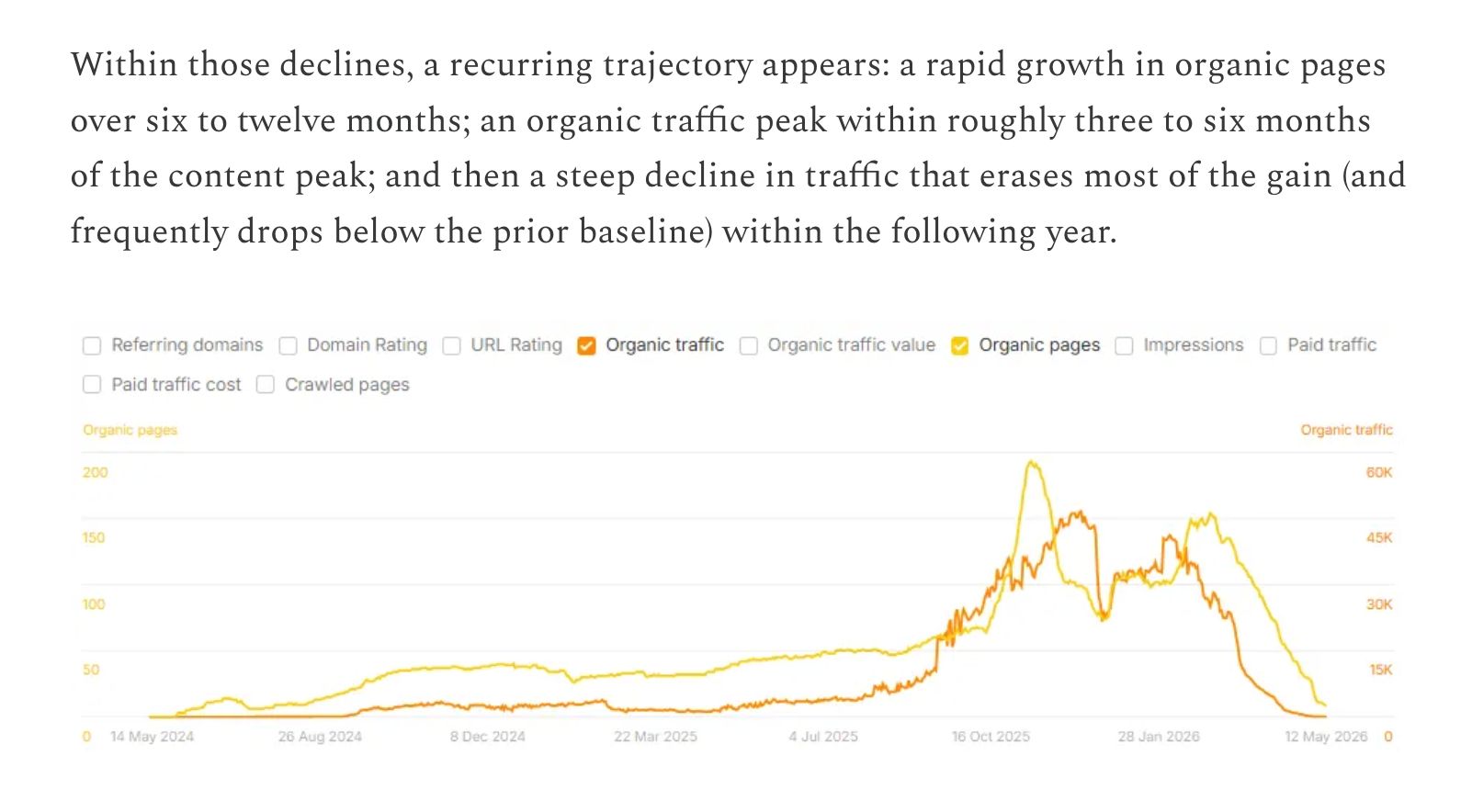
An example of a “Mount AI” traffic graph from Lily’s article.
Many marketers are now unwilling to use generative AI in any capacity for fear Google will punish them. But is Google punishing these websites for using AI content? Or is their AI use incidental to the fact that they’re making spammy, scaled content?
We set out to answer four questions that might shed some light on the issue:
- Are there any fully AI-generated pages in top-ranking positions?
- How common is AI-generated content throughout the top 10?
- Does Google index content with a very high likelihood of being AI?
- Does the organic performance of AI-generated content tank within a few months?
Based on this research, I believe that Google is not against AI content; it is against bad content, but confusion arises because AI content and bad content overlap a significant amount of the time.
- 5.3% of top-ranking (positions 1–3) pages are 100% AI-generated, and 9% are ≥80% AI content—so fully AI-written pages can and do rank at the very top.
- Pages with under 50% AI content account for 82.2% of top-3 rankings, meaning heavily AI-generated content is still a minority at the top.
- Every position in the top 10 contains a meaningful share of heavily AI-generated pages: between 8.4% (position 1) and 11.7% (position 10) of pages have ≥80% AI content.
- Average AI content level rises only slightly from position 1 (27.1%) to position 10 (30.9%), and the median tells a similar story, climbing from 17.1% to 19.5% over the same range.
- Indexation rate drops from 49.28% for low-AI-content pages to 40.35% for very-high-AI-content pages: a meaningful but far from disqualifying gap.
- Even in the very-high-AI-content bucket, 40% of pages were still indexed, showing no binary block on AI-generated content entering the index.
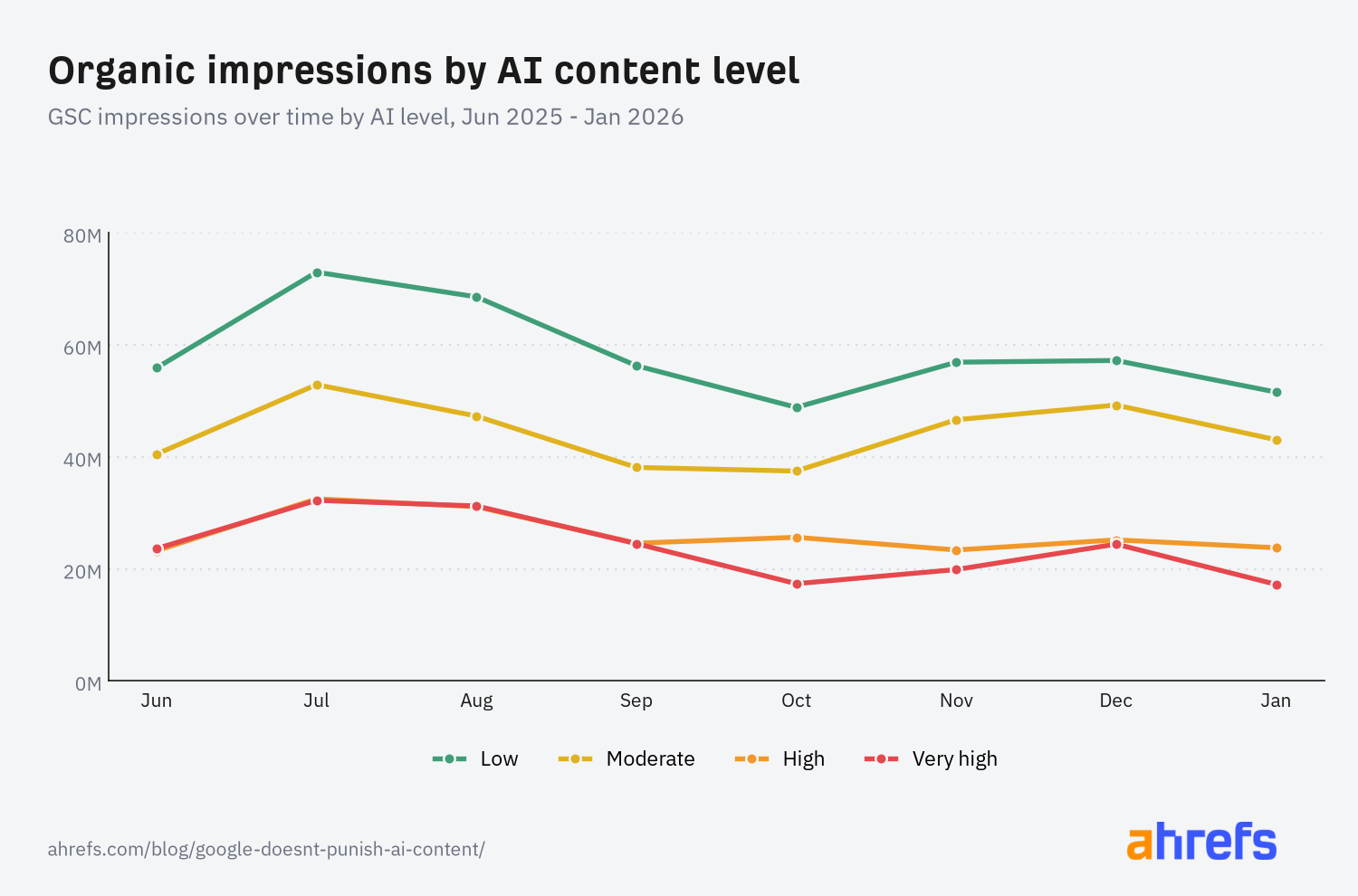
- Low and moderate AI-content pages received 2–3x the organic impressions of high or very-high AI-content pages, the starkest performance gap found in the study.
- High and very-high AI-content pages showed similar, stable impressions over time with no precipitous drop-off.
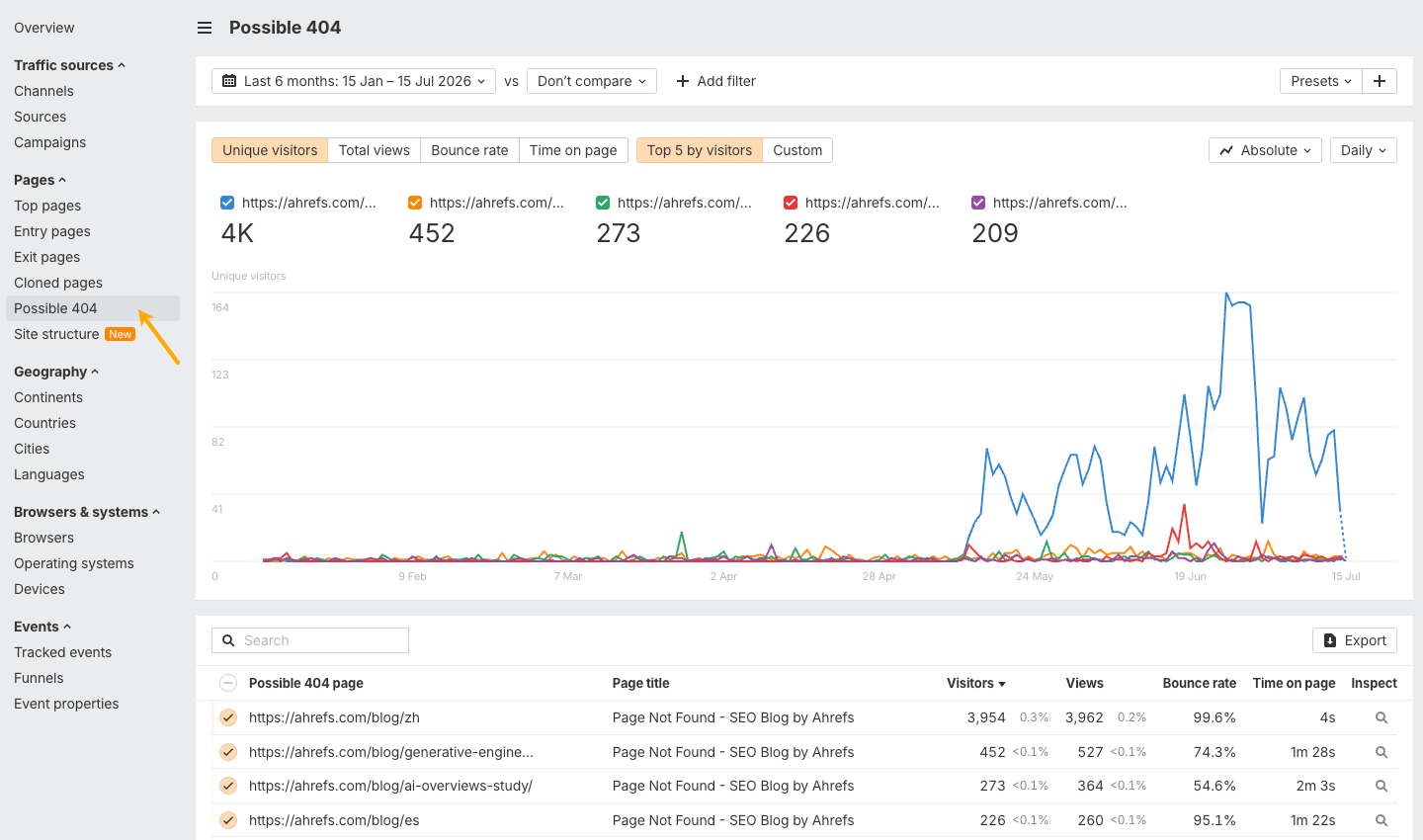
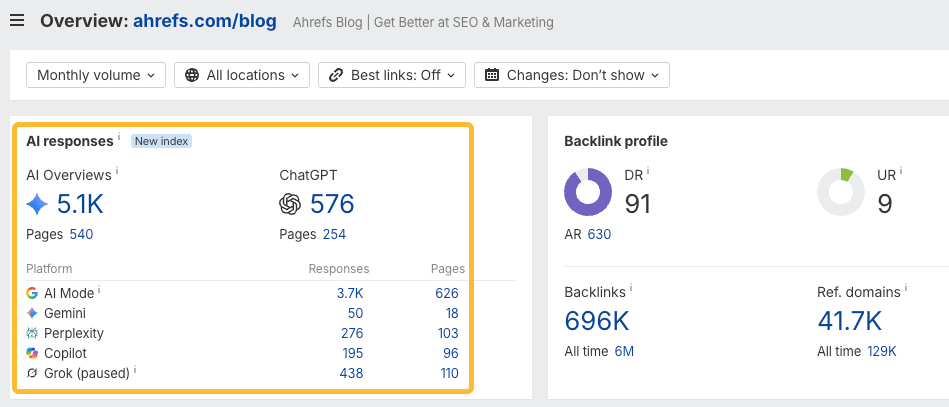
This research uses Ahrefs AI content detector, which Ahrefs customers can use via Site Audit and the Top pages and Page inspect reports in Site Explorer.
AI content levels indicate the estimated percentage of AI-generated text on the page, ranging from low (<20%) to very high (≥80%). For greater accuracy, AI detection only triggers on pages at least 350 words in length.
Importantly, AI content detection is not perfect, and the way we detect AI content will be different from how Google does (if it does).
In the same way that an LLM uses probability to generate text, AI detectors use probability to classify it. This type of research is, in my opinion, the best way to use AI content detection: looking at large-scale datasets and directional trends, and not fixating on individual articles and their AI content.
We analyzed 1,000,000 pages pulled from the top 10 positions in 100,000 SERPs in June 2026. Around 300,000 of these pages were available in our crawler database, of which 150,000 contained enough page content for AI detection.
We found that the majority of top-ranking pages are predominantly human-written. 54.7%—over half—have less than 20% AI content. Together, pages with under 50% AI content account for 82.2% of top-3 rankings.
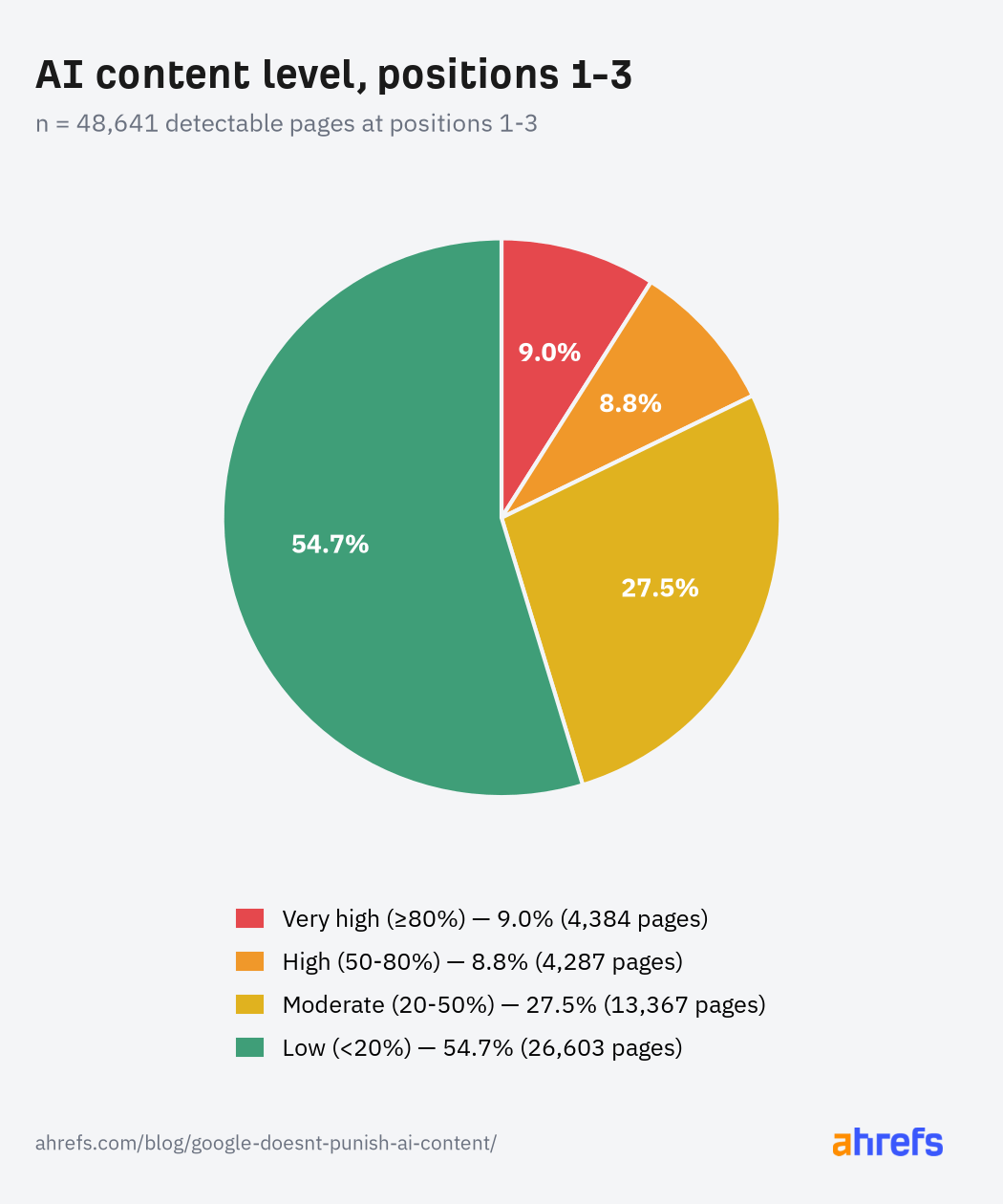
But although our data suggests that higher AI use is correlated with lower ranking positions, it also suggests that it is possible for fully AI-generated content to rank in positions 1-3.
Fully or near-fully AI-generated pages are a small minority, but they certainly exist in this sample: 9% of top-ranking pages are ≥80% AI content, and 5.3% are 100% AI-generated.
Here’s how the data breaks out:
- 5.3% of top-ranking pages returned an AI content level of 100%.
- 9.0% of top-ranking pages returned an AI content level of ≥80%.
- 8.8% of top-ranking pages returned an AI content level of 50-80%.
- 27.5% of top-ranking pages returned an AI content level of 20-50%.
- 54.7% of top-ranking pages returned an AI content level of <20%.
But what about the rest of the SERP?
Looking at the distribution of AI-generated content across the top 10 positions, highly AI-generated content gets rarer as you move higher in the SERP.
Position 1 has the highest share of low-AI-content pages and the lowest share of very-high-AI-content pages:
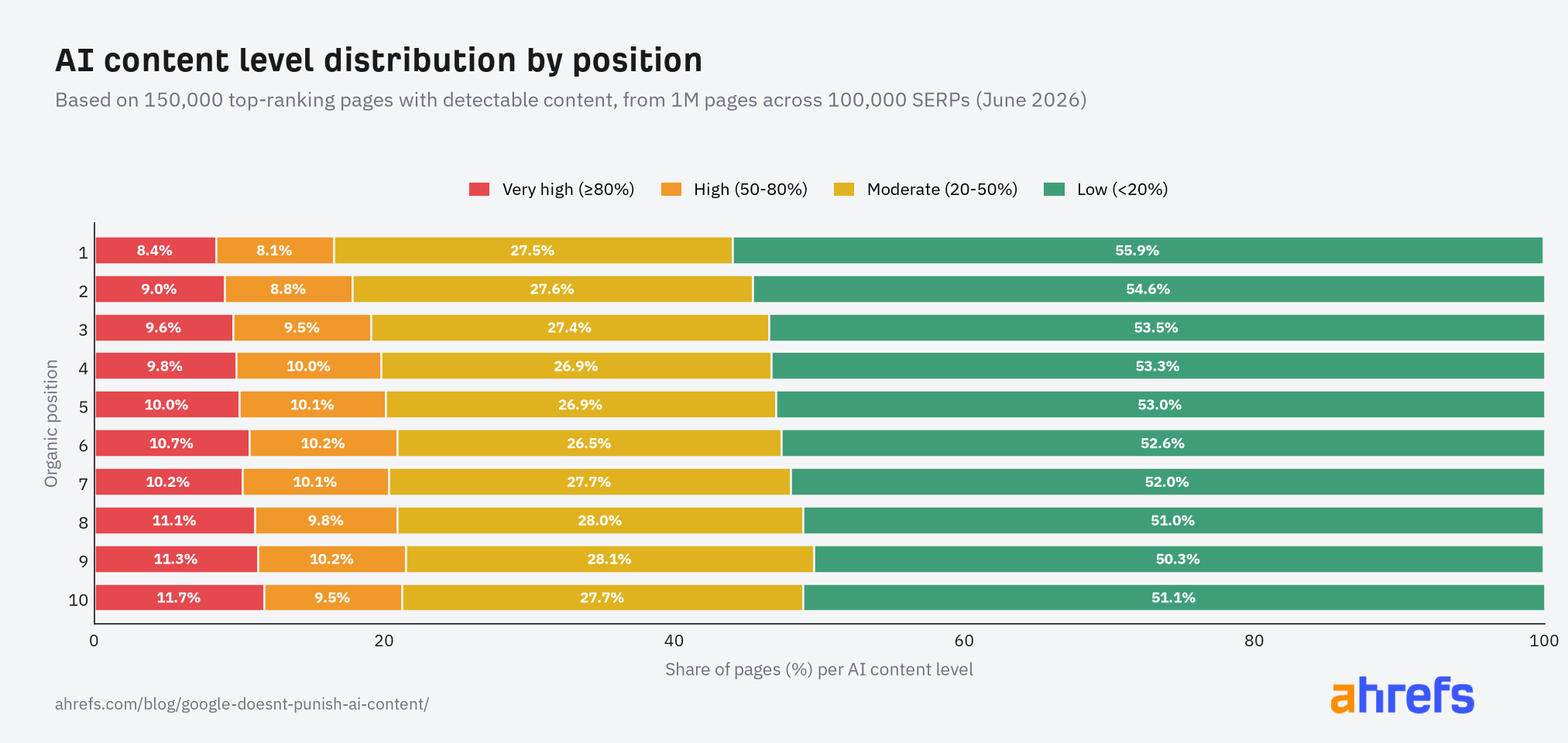
But there is a gentle gradient: the prevalence of AI-generated content gets gradually rarer moving from position 10 to 1, in relatively small increments.
Every ranking position, including position 1, still contains a meaningful share of heavily AI-generated pages: between 8-12% containing ≥80% AI content.
| Position | Very High (≥80%) | High (50-80%) | Moderate (20-50%) | Low (20%) |
|---|---|---|---|---|
| 1 | 8.4% | 8.1% | 27.5% | 55.9% |
| 2 | 9.0% | 8.8% | 27.6% | 54.6% |
| 3 | 9.6% | 9.5% | 27.4% | 53.5% |
| 4 | 9.8% | 10.0% | 26.9% | 53.3% |
| 5 | 10.0% | 10.1% | 26.9% | 53.0% |
| 6 | 10.7% | 10.2% | 26.5% | 52.6% |
| 7 | 10.2% | 10.1% | 27.7% | 52.0% |
| 8 | 11.1% | 9.8% | 28.0% | 51.0% |
| 9 | 11.3% | 10.2% | 28.1% | 50.3% |
| 10 | 11.7% | 9.5% | 27.7% | 51.1% |
We also calculated the average and median AI content level across a sample of 15,000 pages for each position. It’s a similar story: AI content becomes more common further down the SERP, but still appears in higher positions:
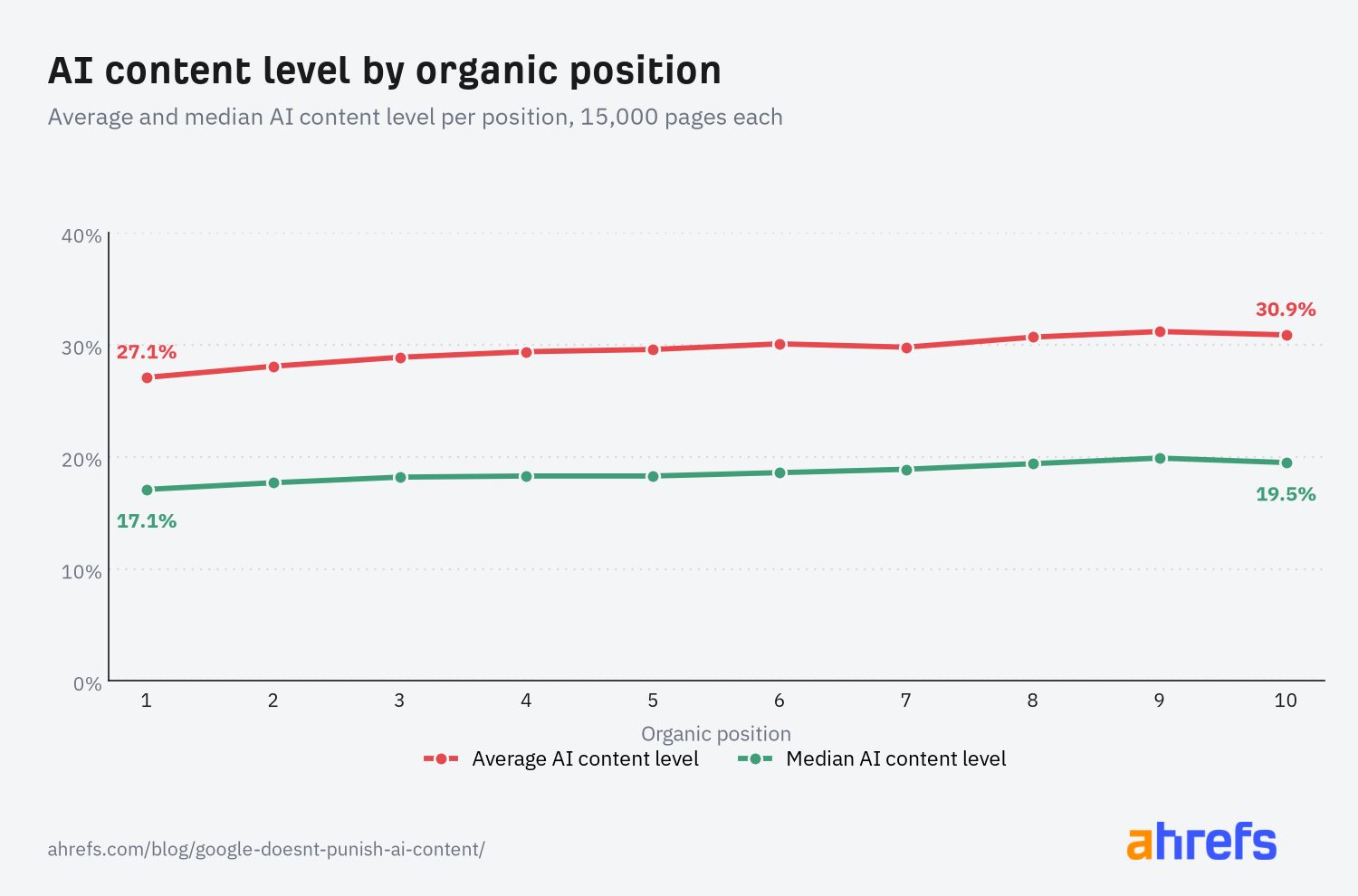
| SERP Position | Average AI Content Level | Median AI Content Level |
|---|---|---|
| 1 | 27.1% | 17.1% |
| 2 | 28.1% | 17.7% |
| 3 | 28.9% | 18.2% |
| 4 | 29.4% | 18.3% |
| 5 | 29.6% | 18.3% |
| 6 | 30.1% | 18.6% |
| 7 | 29.8% | 18.9% |
| 8 | 30.7% | 19.4% |
| 9 | 31.2% | 19.9% |
| 10 | 30.9% | 19.5% |
Analysing ranking pages introduces a type of selection bias: we are only evaluating successful URLs that Google has already deemed fit for indexing. But does AI use reduce the chance of a URL being indexed in the first place?
We looked at the indexation rates for buckets of pages with different AI content levels. We sampled 1,000,000 pages from our crawler database, 1 page per domain. Around 100,000 pages contained enough content for AI detection. We counted a page as indexed if it had any of the following traits:
- At least one identifiable organic keyword ranking, or
- At least one GSC impression since January 2026, or
- An exact URL hit for a Google site: search.
If we bucket pages by their estimated AI content level, we can see that higher AI content levels correlate with lower indexation rates:
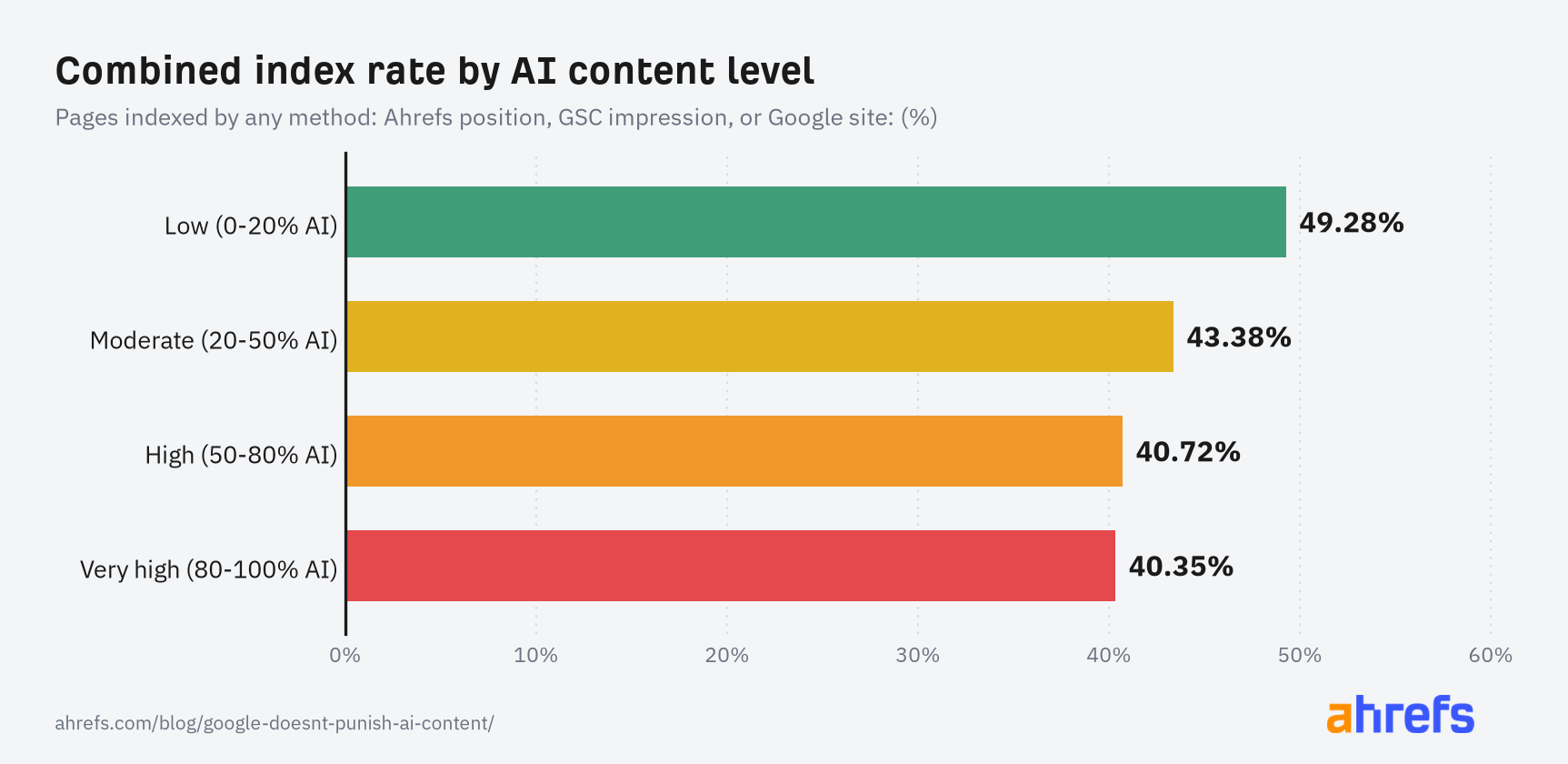
Here’s how the data breaks out by bucket:
- Pages with low AI content level had an indexation rate of 49.28%
- Pages with moderate AI content level had an average indexation rate of 43.38%
- Pages with high AI content level had an average indexation rate of 40.72%
- Pages with very high AI content level had an average indexation rate of 40.35%
While the indexation rate is lower for content with high or very high AI content levels, a full 40% of these pages were still indexed—not a million miles away from the 49% indexation rate of low AI content.
Finally, we wanted to see how the organic performance of AI-generated pages trended over time relative to non-AI-generated pages.
To do this, we used GSC data from live URLs, matched those URLs with our crawler database, filtered out pages with too little text for AI detection, and then bucketed the URLs by their estimated AI content level. This left us with the following samples:
- Low AI content level: 28,643 pages
- Moderate AI content level: 23,498 pages
- High AI content level: 12,911 pages
- Very High AI content level: 15,809 pages
For each bucket, we used GSC data to plot the change in impressions over time, starting with one panel of websites from June 2025 to January 2026…
…and a second panel of websites from January 2026 to June 2026:
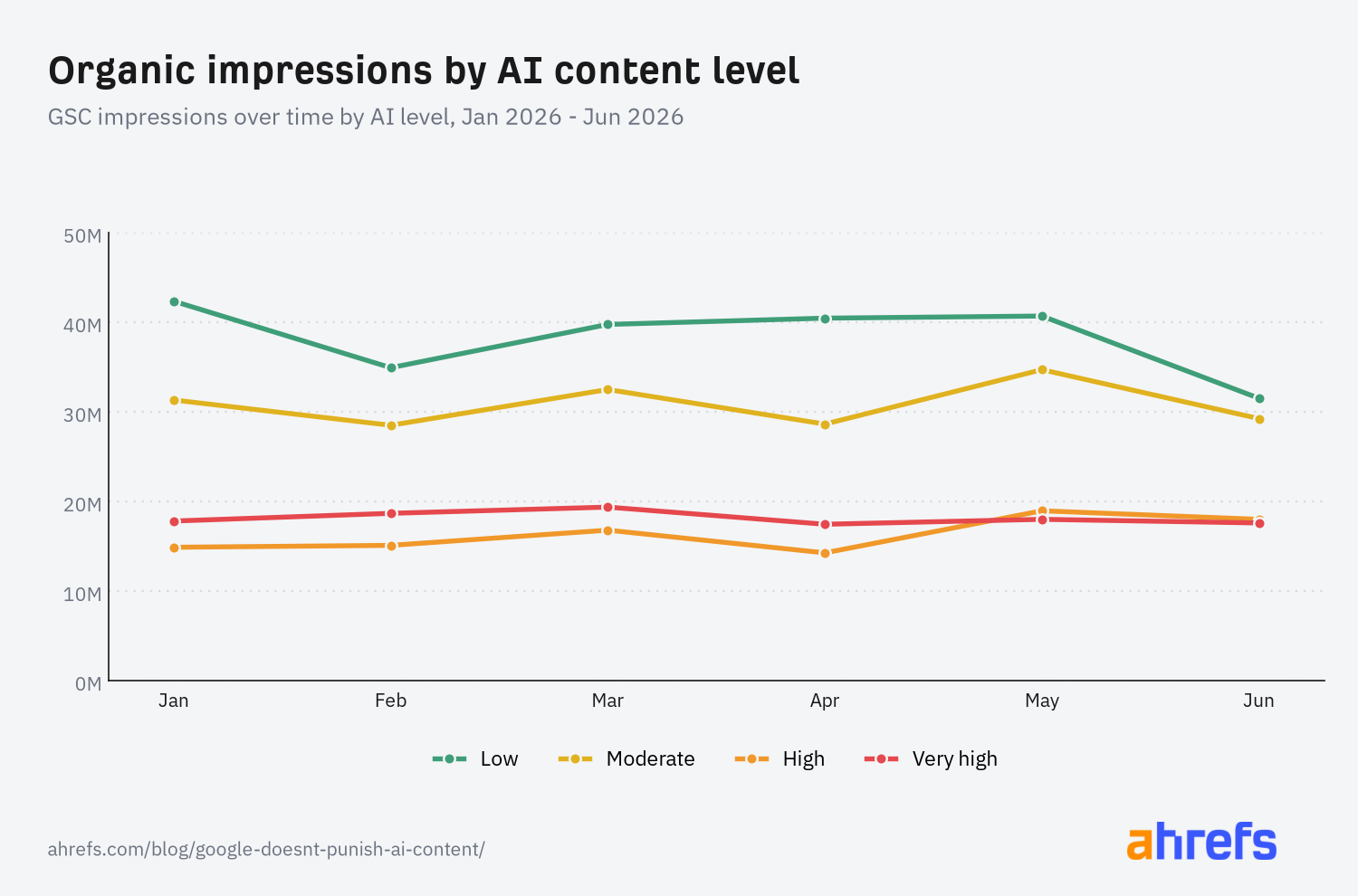
Organic performance is obviously influenced by many, many factors, and there are few concrete conclusions we can draw from this limited time window, but I thought the data was interesting for a few reasons:
- Generally, AI content use seems negatively correlated with impressions.
- Low and moderate AI level content received 2–3x the impressions of high or very high AI-generated content.
- High and very high AI-generated content both received similar impressions across both samples.
- There are no obvious precipitous drops in impressions for highly AI-generated content.
There are many reasons why AI-generated content might earn fewer impressions, so it would be wrong to assume that there is any kind of automatic suppression happening. Sites that lean heavily on AI content may tend to be newer or lower-authority in the first place; inversely, sites with good organic performance may be disincentivized to publish AI content.
Most likely, in my opinion, is that increasing use of AI correlates with decreasing content quality. I think this is the key to understanding how Google treats AI content.
Throughout this research, AI use seems to be correlated with lower performance in search: lower impressions, lower ranking position, and lower indexation rate.
But this doesn’t tell the entire picture. AI-generated content is found in significant amounts in every ranking position, including the top 1 to 3. A significant amount of AI-generated content is successfully indexed. Impressions to AI-generated content remained relatively stable over time.
There are no obvious hard cutoffs suggesting a binary AI classifier is preventing AI-generated pages from ranking highly or making it into the index. Instead, we see a gradual gradient: performance generally worsens with increasing AI use… probably because content quality generally worsens with increasing AI use.
As I’ve said before, when companies engage in an AI content strategy, they are often engaging in a strategy that is very different from traditional content creation and SEO—different and worse in many ways. Basic AI content often:
- Repeats common knowledge without adding any new information to the SERP.
- Fails to include internal and external links, images, visual interest, and first-person experiences.
- Relies on tedious academic-style writing.
- Contains obvious mistakes and inaccuracies.
These are all problems that could markedly worsen the organic performance of any piece of content, but they are especially common in most AI-generated content. As Dan Taylor explained in his great SEJ article recently, publishing this content at scale is the perfect recipe for your very own “Mount AI” situation, as Google “burst-crawls” new low-quality, AI-generated pages but dumps them from the index soon after:
Google might initially burst-crawl the new setup out of curiosity. But, if the domain lacks the baseline authority to sustain that scale, Google will throttle its resource allocation. Just because Google gives you the resources to index your pages initially, it does not mean it will grant them to you indefinitely.

I don’t think Google is trying to punish AI-generated content; I think it is relying on the same old hallmarks of content quality that it always has. It’s just that AI-generated content is usually lower quality than human-generated content.
Crucially, these quality problems commonly co-occur with AI use, but they are not guaranteed by AI use—as shown by the not-insignificant number of indexed and top-ranking AI-generated pages. I know from firsthand experience that it is very possible to create detailed, interesting, well-researched content using AI generation—the caveat being that most people do not. Yet.
I don’t believe marketers and SEOs should be scared of AI content creation—but they should be scared of spam and scaled content.
Does Schema Markup Impact SERP Rank?
The original methodology was an 8-page Google doc and has been reformatted into collapsible sections in the Methodology section of the original schema study.
For the sake of context, I’ll include the shorter version of it here.
A background of our agency and the study
A quick background of our agency gives more context to the study and why this industry was chosen for the experiment.
We’re a digital marketing agency for landscaping and lawn care businesses (as well as other green and outdoor living businesses). Our clients are strictly local and are extremely similar in scale, strategy, and services.
On top of this, we require nearly all new clients to have their site built or rebuilt by us using a templated site theme we built on WordPress. The only real difference between the sites is the branding, images, content, and localization.
The purpose of this study was to determine whether or not schema markup was an effective method for improving rank for our clients, given their local business classification.
The schema markup we used
One of the main considerations for this was determining which schema to use. While some client sites had blog posts, FAQs, and job listing pages, others did not. We needed schema markup that could be consistent with every test subject.
So with that, we went with LocalBusiness markup from schema.org. We had even consulted with Jarno Van Driel, Yoast, and Moz on the items and types within the LocalBusiness markup to be used in this study.
The biggest consideration in the schema markup used was the idea that we wanted to isolate the mere fact of the schema being added to the site, which affects rank, and not the idea that a higher click-through-rate (CTR) through rich snippets affects rank.
Aside from JobPosting schema, there isn’t much in the local service industry that produces rich results, especially with FAQ rich snippets being deprecated completely and only used on government and health organizations after August of 2023.
With that in mind, we avoided any schema markup that aided in producing rich snippets that were still applicable, such as priceRange or reviewRating schema.
The full markup used can be found in the original study under the “Methodology” section.
The pre-test & client sorting
With any controlled experiment, the hardest part is determining subjects that are eligible for the test. Out of our 50 clients, we found 29 that were eligible.
These 29 were:
- Only on our base-level SEO services
- Located in the US
- Had a site built by us (WordPress using Divi)
- Were not producing new or regular content
- Had been continuously working with us for six months or longer
These 29 clients would then be sorted into two groups:
The Control Group would have all SEO efforts paused and no schema added to their site. The Test Group would also have all of their SEO efforts paused; only this group would receive the LocalBusiness schema.
A unique challenge with our industry is that search volume and competition are seasonal. Knowing that we were conducting this experiment between February and April, it’d be landing right at the beginning of the spring rush. Our Southern clients don’t feel that rush as much as our Northern clients coming out of a snowy winter.
To control the seasonal variable, we’d ensure both the control and test groups would have an equal number of clients in various US geographical locations.
5 AI Search Trends I’m Seeing in 2026, Backed by Ahrefs Data
AI search is the most consequential thing to happen to our industry in a decade… and the most over-narrated.
Every week brings a new acronym, a new era, a new thing you are supposedly already too late for.
Some of it changes how we work, but a lot of it is—let’s be honest—noise.
Well, fear not.
I’ve curated some genuine AI search trends that have been building throughout the year, backing up my observations with cold, hard search volume and social media discussion—with a little help from Keywords Explorer and Letaido.
Ever since ChatGPT launched in 2022, marketers have wanted to know whether their brand gets recommended in AI answers.
Demand for AI visibility tools has exploded over the last year more than any other, with searches like “ai search tracking” up 184%, and “ai rank tracking” up 175%.
“AI search tracking” US monthly search volume. Source: Ahrefs Keywords Explorer.
Recently, Google rolled out an AI performance report in Search Console, breaking out visibility inside AI Overviews and AI Mode.
Brodie Clark called it “the most requested report in Google Search Console ever”—the appetite for any visibility data is that strong.
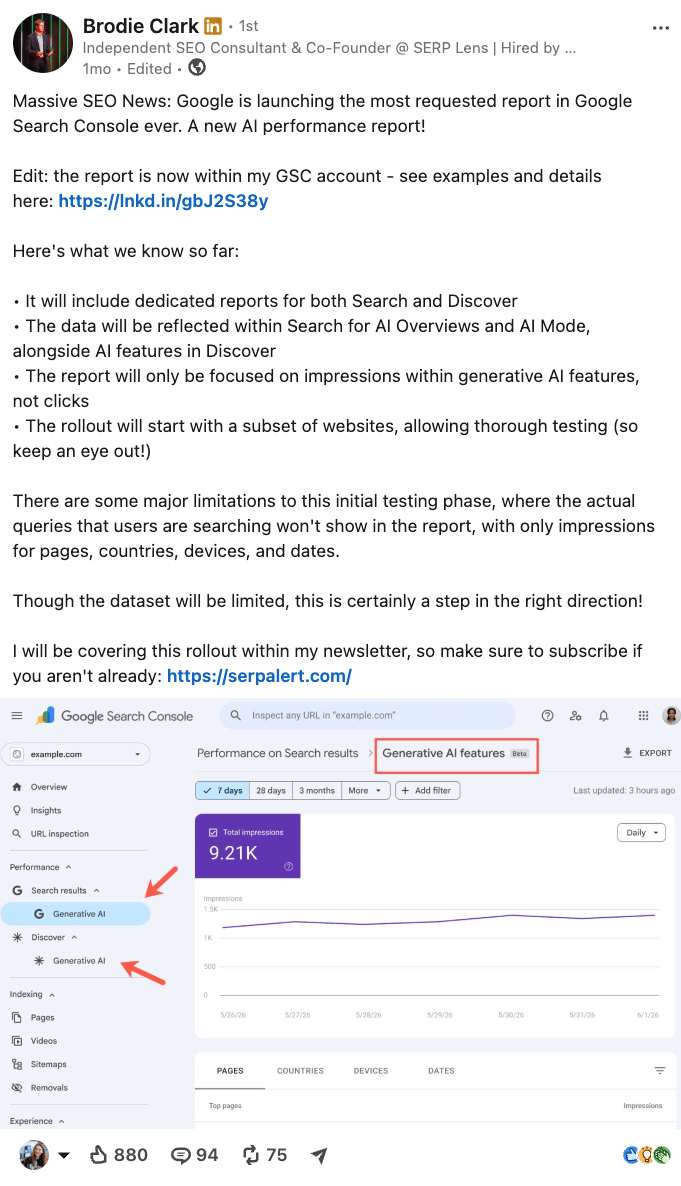
The launch drew a packed r/SEO thread within hours, but most of it centered around the report’s limitations.
The main one being that clicks and queries aren’t shown—only impression data.
Under Google’s official announcement, TUI’s Technical SEO Manager Simone De Palma asked why marketers should be satisfied with a sub-menu that aggregates AI Overview and AI Mode impressions together with no referral distinction, when Bing at least surfaces the RAG queries behind its answers.
The industry is mostly in agreement that earning a citation is the fast, controllable way to show up in an AI answer—far quicker than the slow, opaque hope of getting baked into a model’s training data.
But they also agree that surface-level citation data is not enough.
The harder question we’re all beginning to ask is: what is an AI citation actually worth?
Does it actually send someone to our site and do they convert, or is it just a vanity reference sitting in an answer nobody acts on?
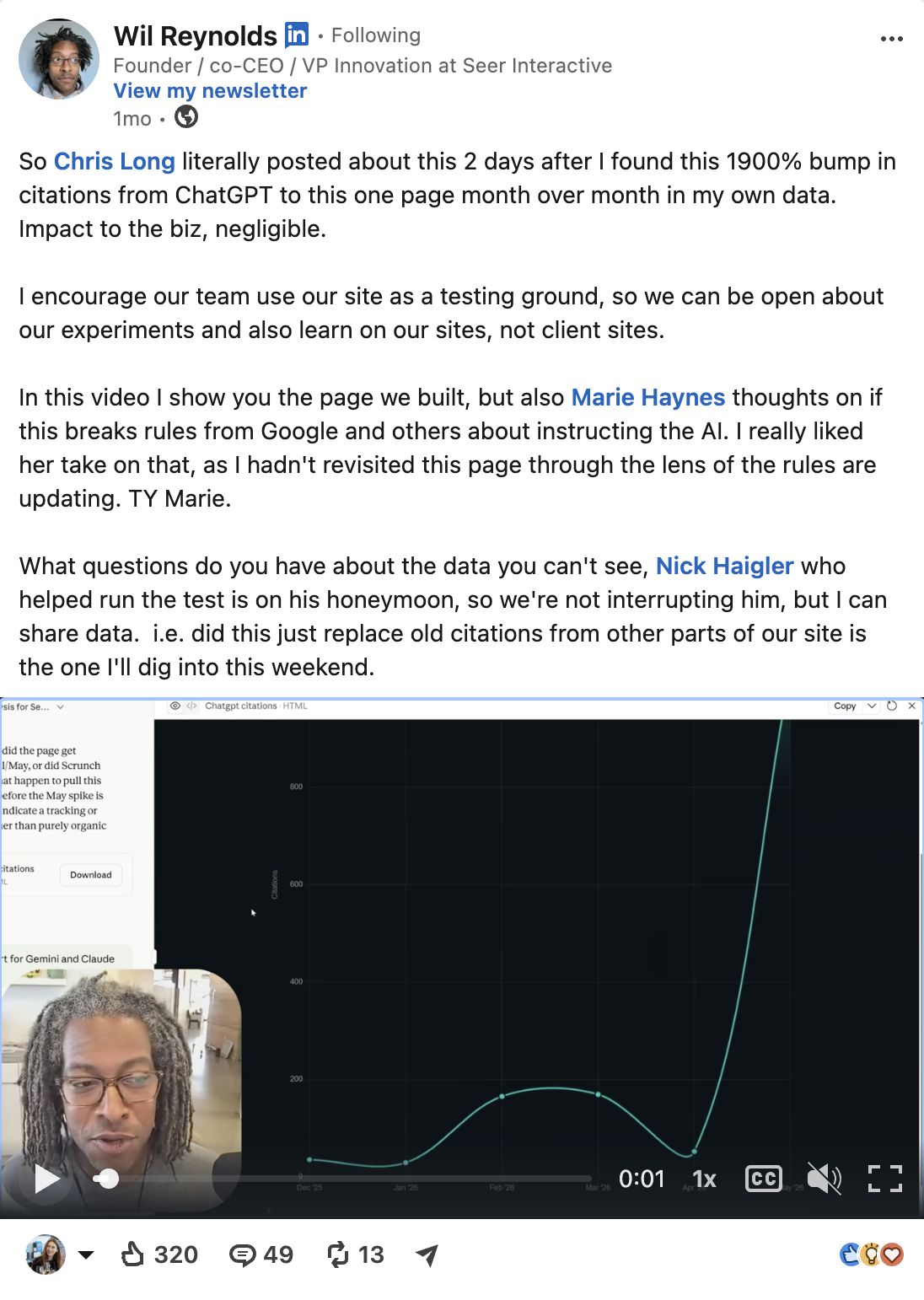
Wil Reynolds got SEOs and marketers debating the topic of AI ROI on LinkedIn when he shared the results of an experiment he ran on his personal site.
He noticed a 1,900% month-over-month jump in ChatGPT citations to a single page, then quickly realized it made little-to-no business impact.
The shift from counting mentions to interrogating their value is a genuine, developing trend in AI search over the last twelve months—spawning an entire measurement vocabulary.
Every trending keyword in the table below reflects this.
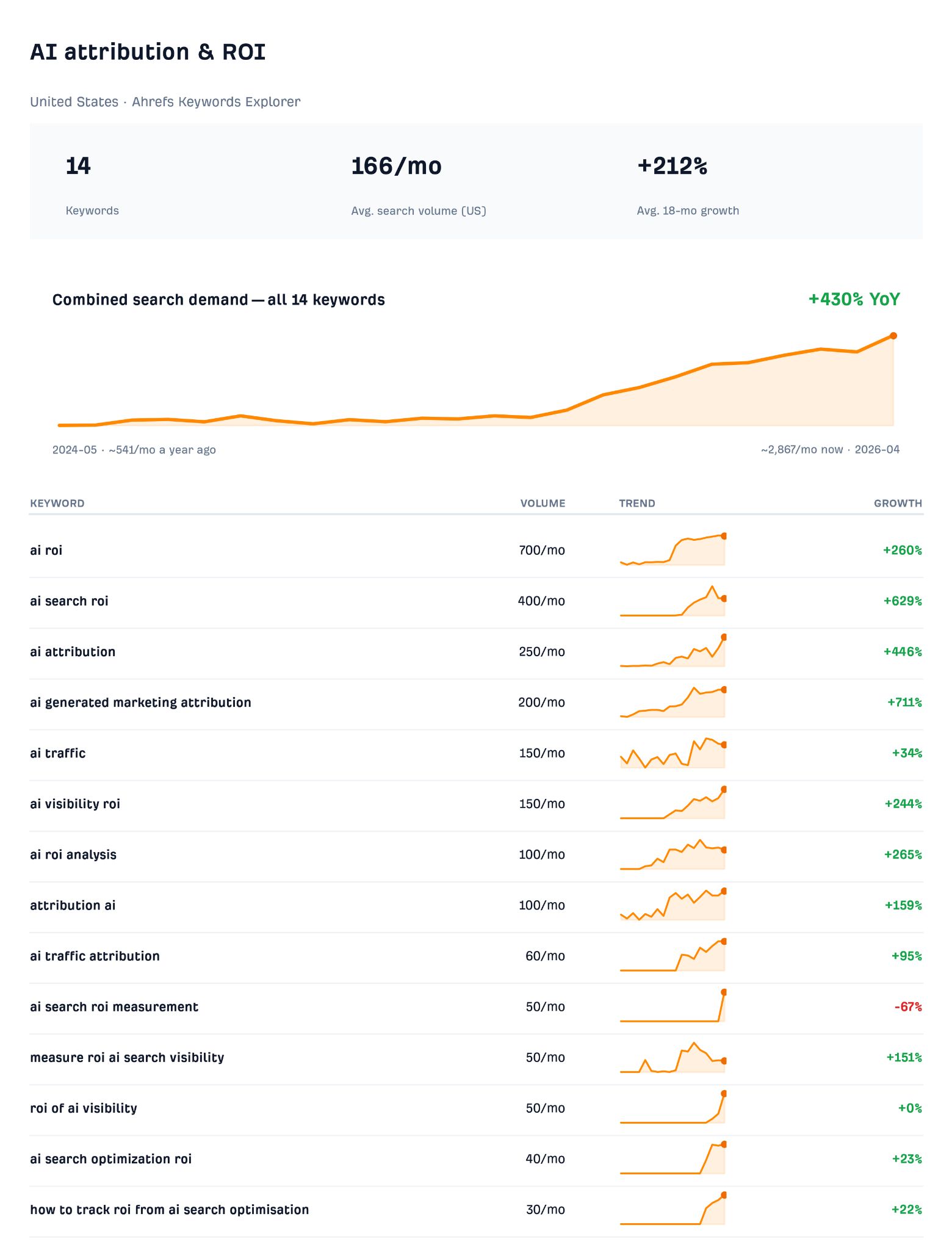
This table shows just a small sample of keywords—some with pretty modest volumes—but having scanned Matching Terms, Related Terms, and Search Suggestions reports in Ahrefs Keywords Explorer, I can confidently reassure you that there are tons of these synonymous searches.
Marketers have realized that some citations are only worth chasing when they send people to your site, and when those people act.
This is the kind of data you can see in Ahrefs Brand Radar. It shows you which of your cited pages are actually picking up real AI traffic.
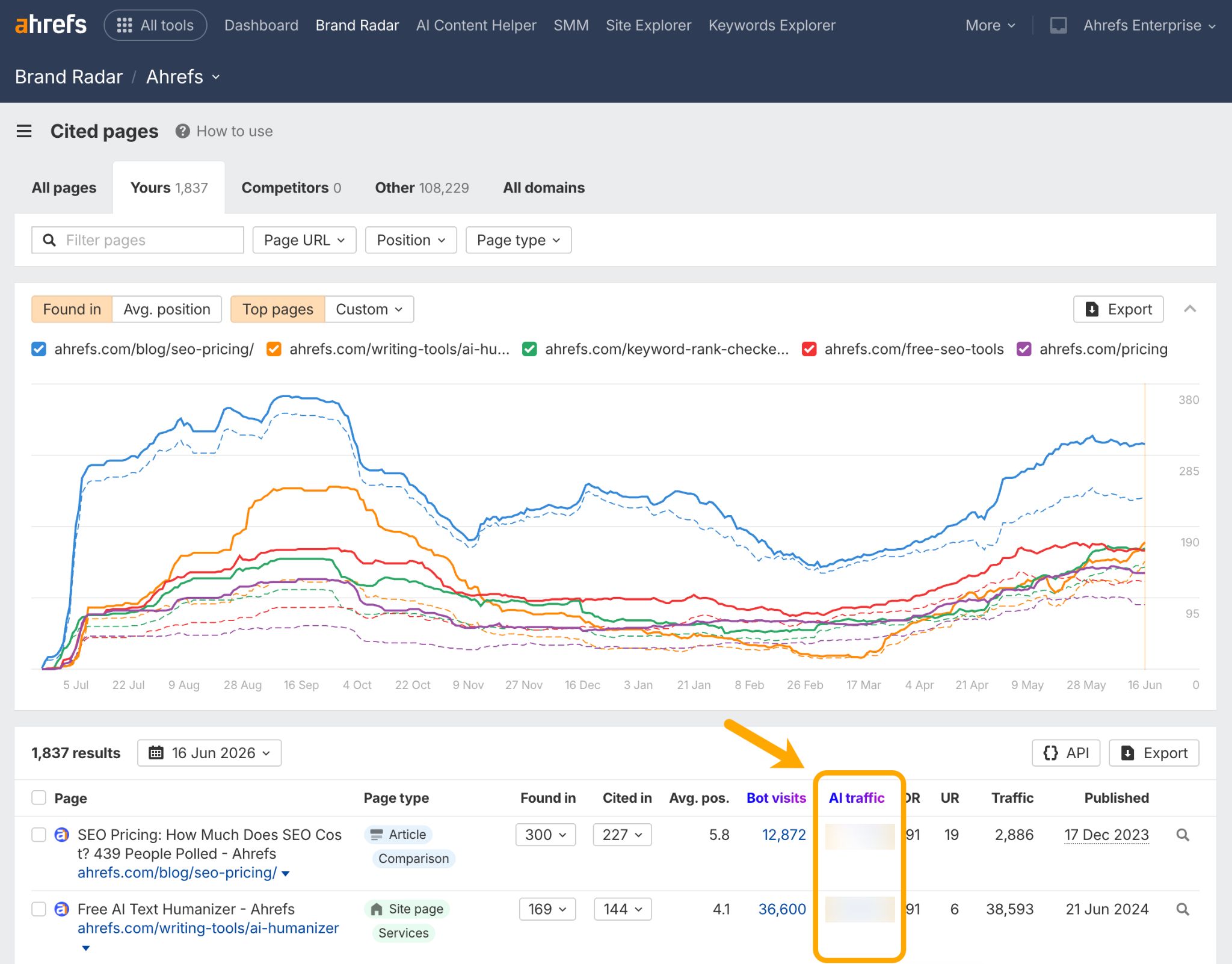
From there you can check Web Analytics, to trace real events and conversions back to their AI source.
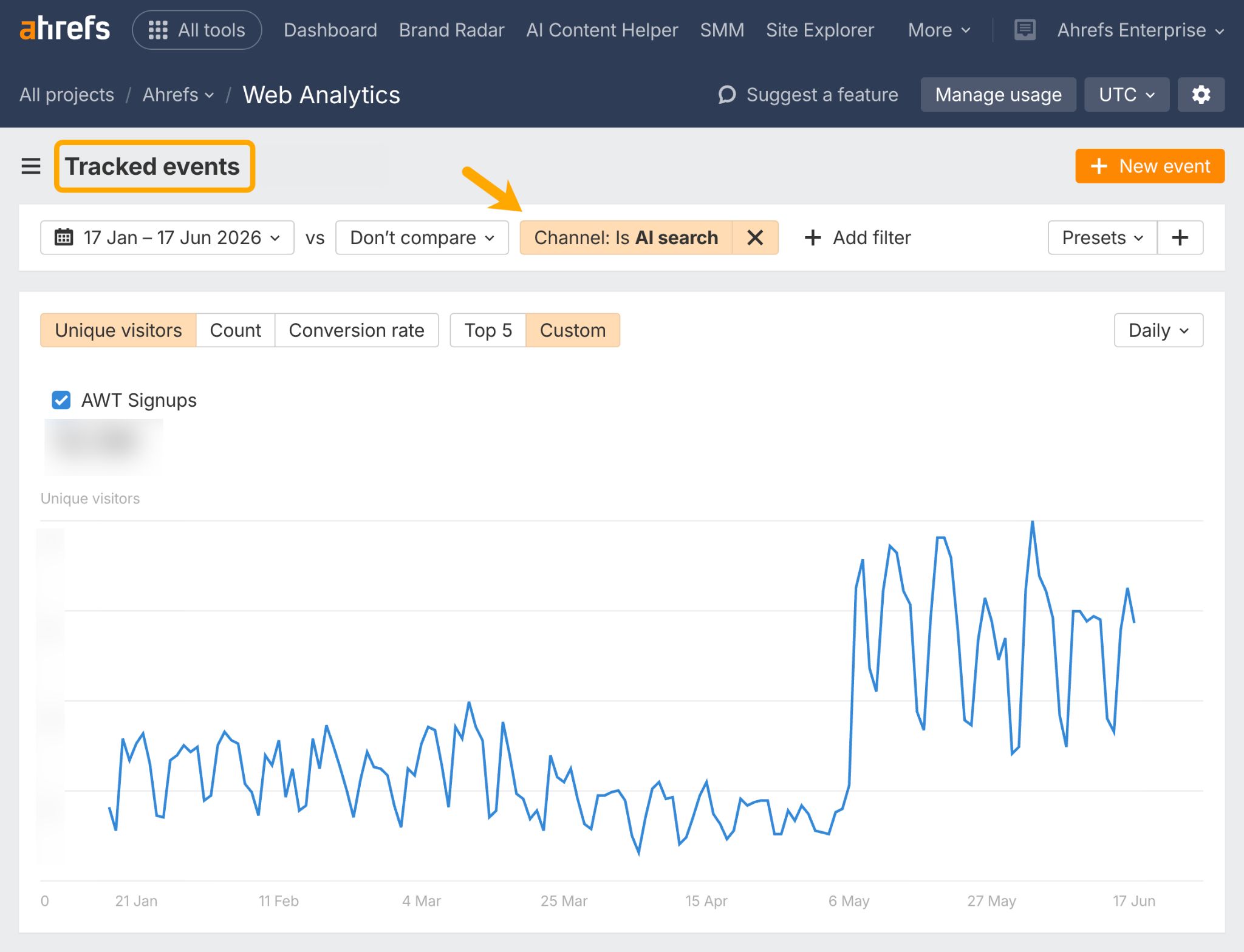
A growing number of the “readers” you’re attempting to influence are actually AI agents browsing and buying on your audience’s behalf.
In fact in June 2026, Cloudflare CEO, Matthew Prince, revealed that agentic (bot/crawler/agent) traffic had surpassed the 50% mark for the first time in the history of the internet.¹ ²

Over the past two years agentic AI has grown into mainstream demand in its own right, and trailing it, a small but unmistakably new set of searches has appeared for optimizing pages so an agent can read and act on them.
Think: “llms.txt” and “agentic seo”.
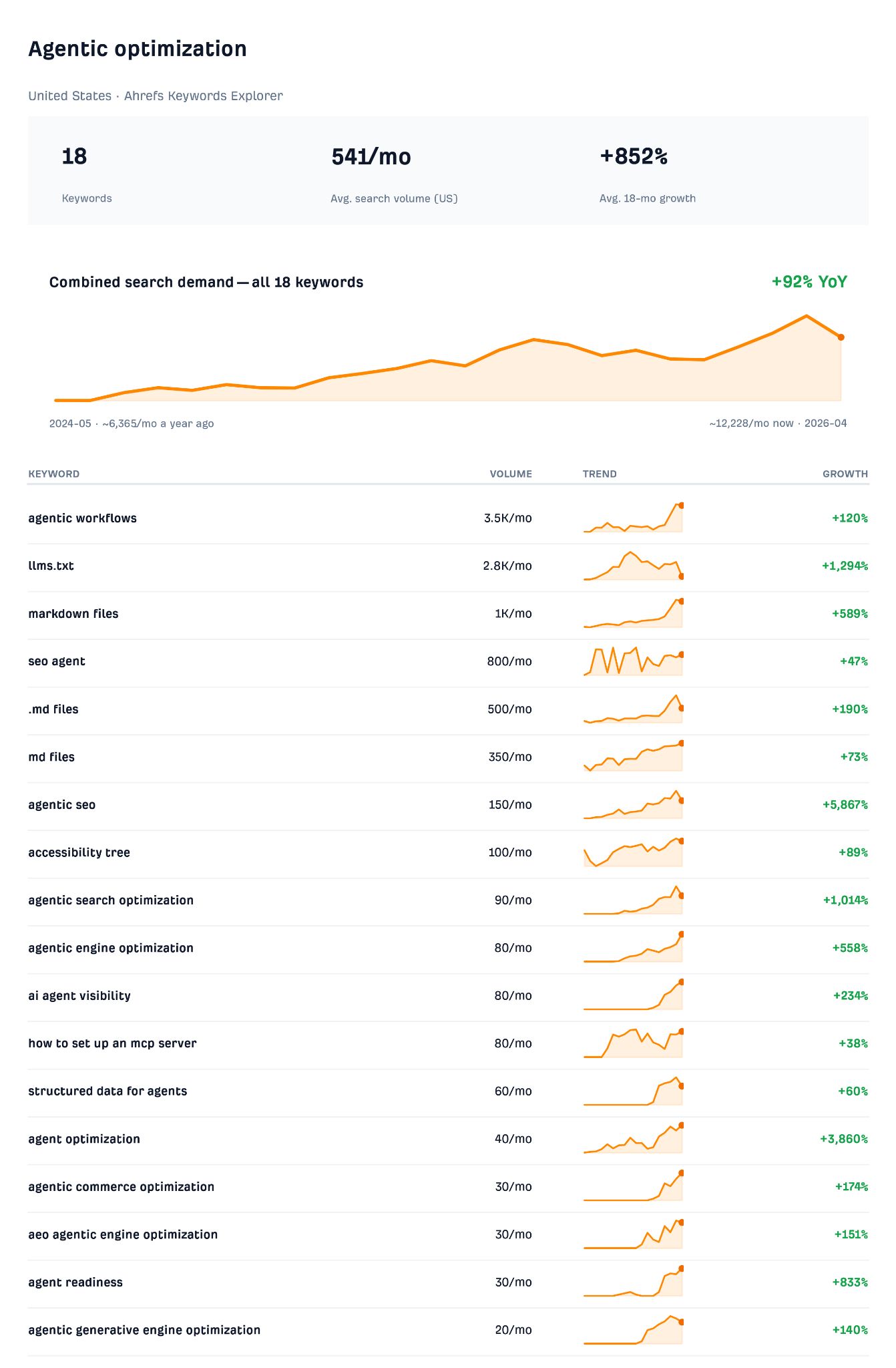
These kinds of agentic optimization topics are trending in the industry right now for multiple reasons.
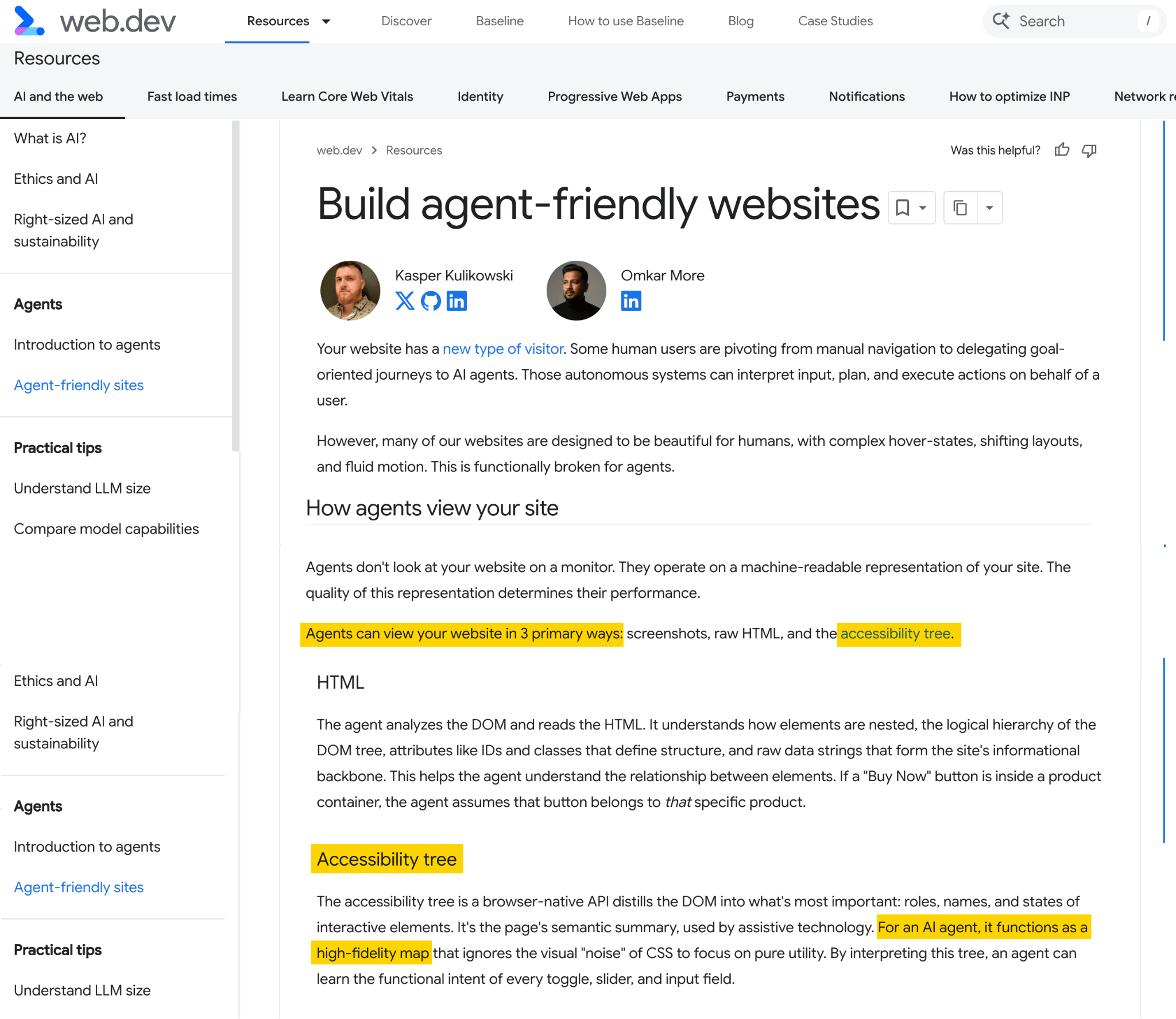
Llms.txt, markdown files, and the accessibility tree are all ways of telling an agent what a page contains, since agents parse structured text far more reliably than they render JavaScript or infer meaning from a layout.
Llms.txt has garnered attention over the last year following constant industry debates over whether it actually improves AI visibility (hence our own study: We Analyzed 137K Sites: 97% of llms.txt Files Never Get Read).
Markdown files also gained traction when sites like Cloudflare began popularizing serving plain-text versions of pages so agents can skip the rendering step entirely.
And the term “accessibility tree” (a feature built for screen-readers to help blind or visually impaired users navigate webpages) spiked when Google began suggesting developers optimize for accessibility tree structure in its web.dev guide.
Adding to this, the Chrome team recently announced an experimental “Agentic Browsing” category at Google I/O, featuring agent readiness checks in Chrome Lighthouse and PageSpeed Insights.
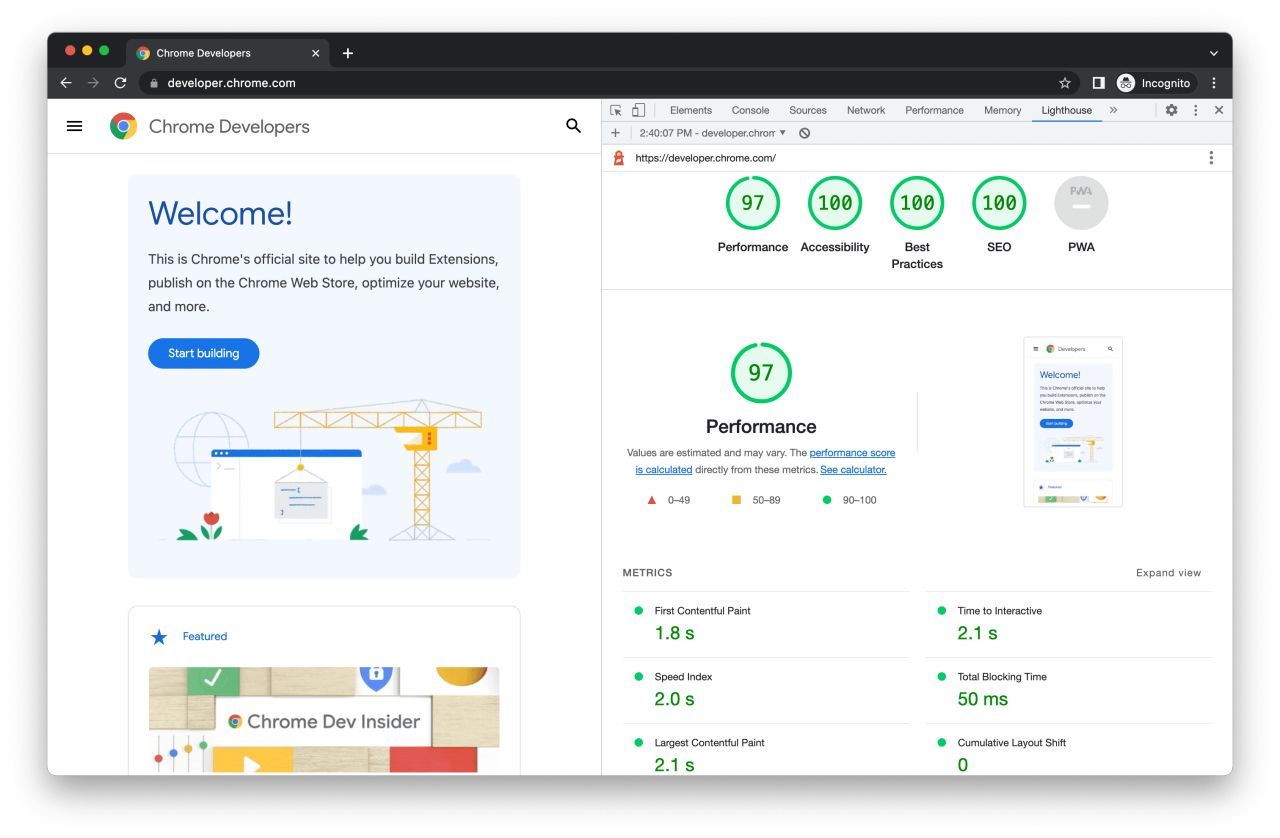
It’s the same audit panel SEOs already open for performance, except this one scores how well an AI agent, rather than a person, can read and act on a page.
This became a big talking point on LinkedIn, and posts sharing the news—like this one from Claudia de Coux—picked up hundreds of likes.
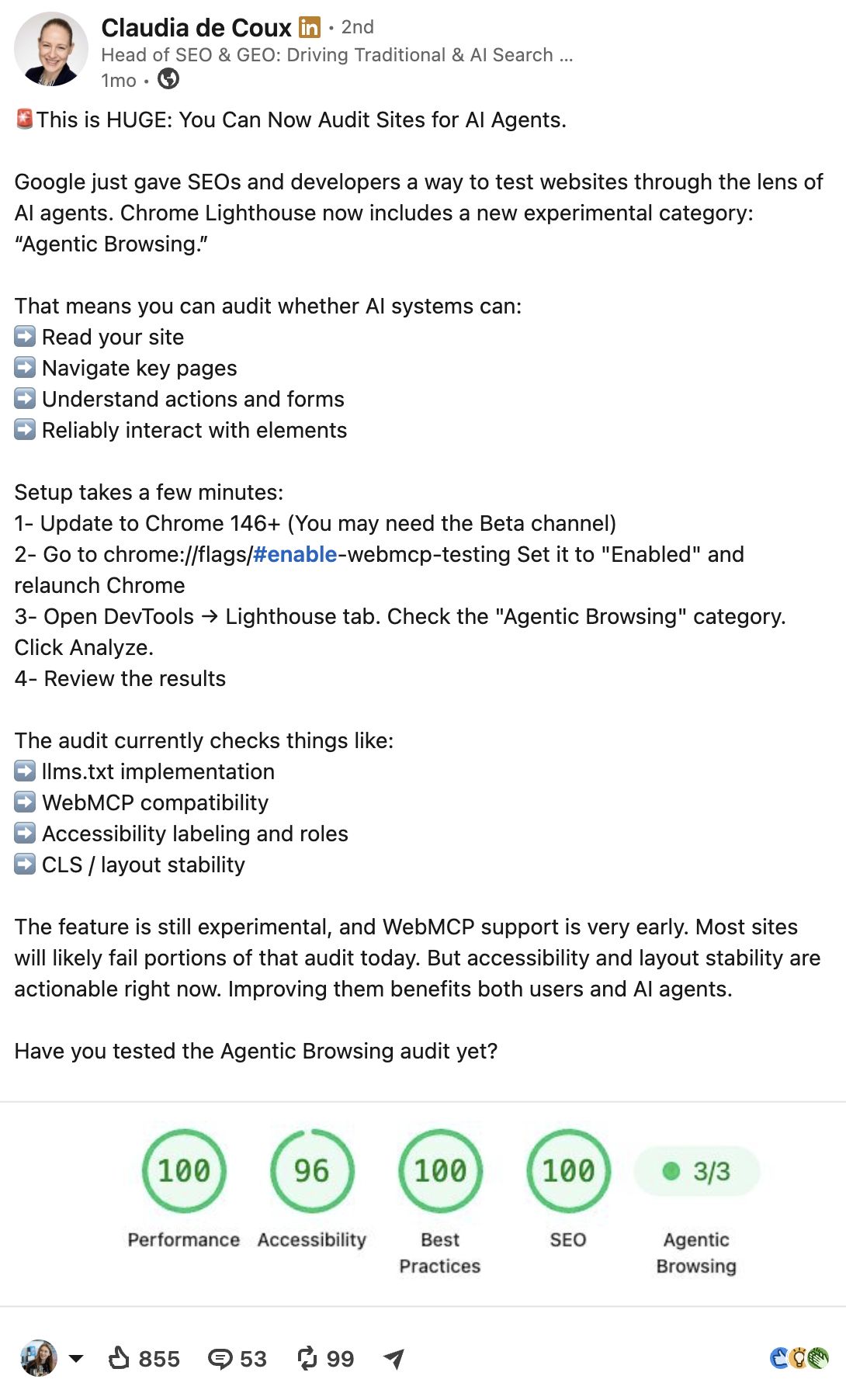
Marketers keep circling back to whether agentic optimization will affect rankings.
Elena Kostova asked directly in the replies under Chrome’s own post: will agentic readiness follow the same path Core Web Vitals did, starting as a Lighthouse audit and ending up a ranking factor?
Nobody knows yet, and that’s exactly why I predict that search volume, forum threads, and social media discussion surrounding agentic optimization will just keep growing.
What you can know today is whether any of this applies to your site.
Ahrefs Bot Analytics shows you which AI agents and crawlers are already hitting your pages, and how often.
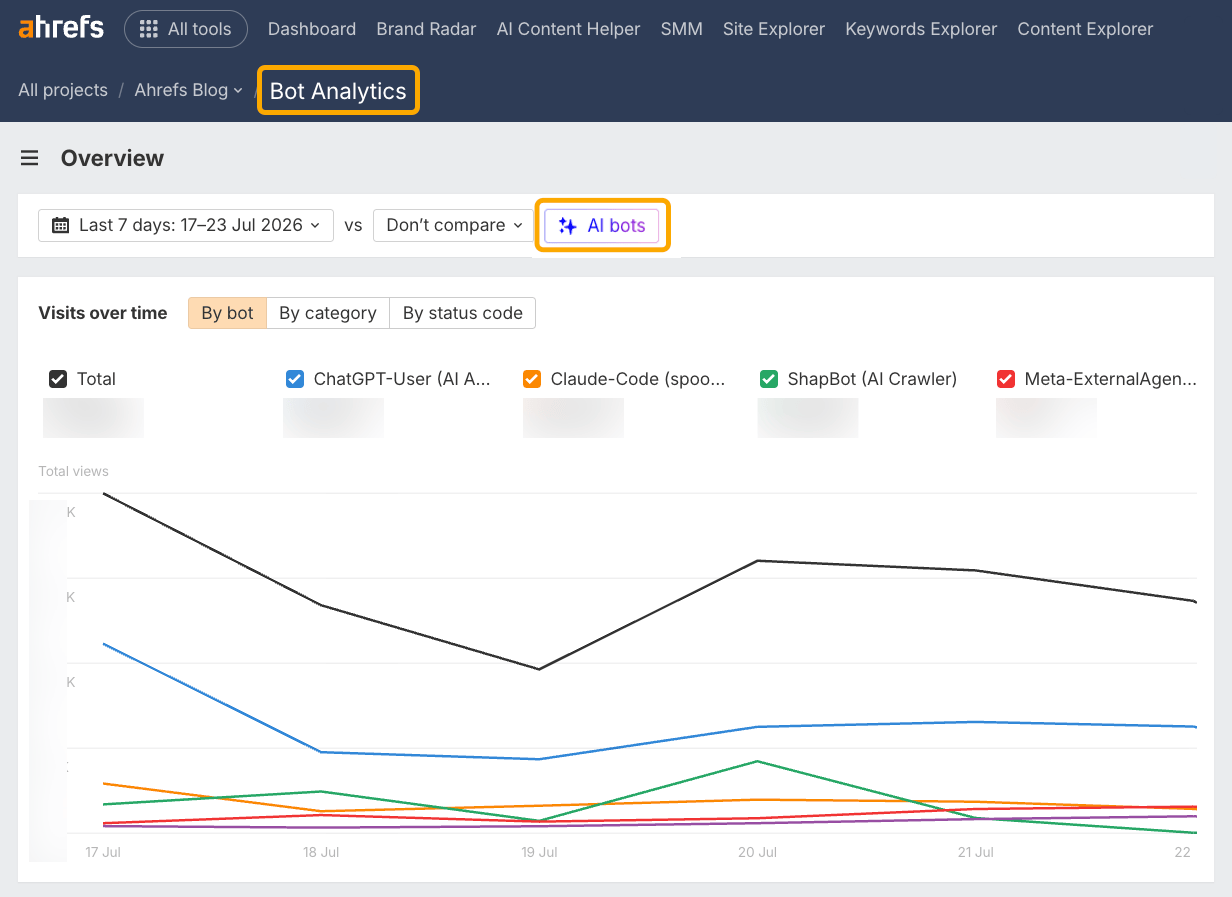
This is a great starting point for optimizing your AI visibility, and a quick way of testing whether Cloudflare’s 50% figure holds true for your own traffic.
As AI search answers more queries on the results page, the clicks that used to reach websites are disappearing.
Over the past year marketers have moved from worrying about it to diagnosing and actively doing something about it.
Searches for “zero-click search strategy,” traffic-loss audits, and a run of “why is my website traffic dropping” queries are all climbing as we all look for a plan.
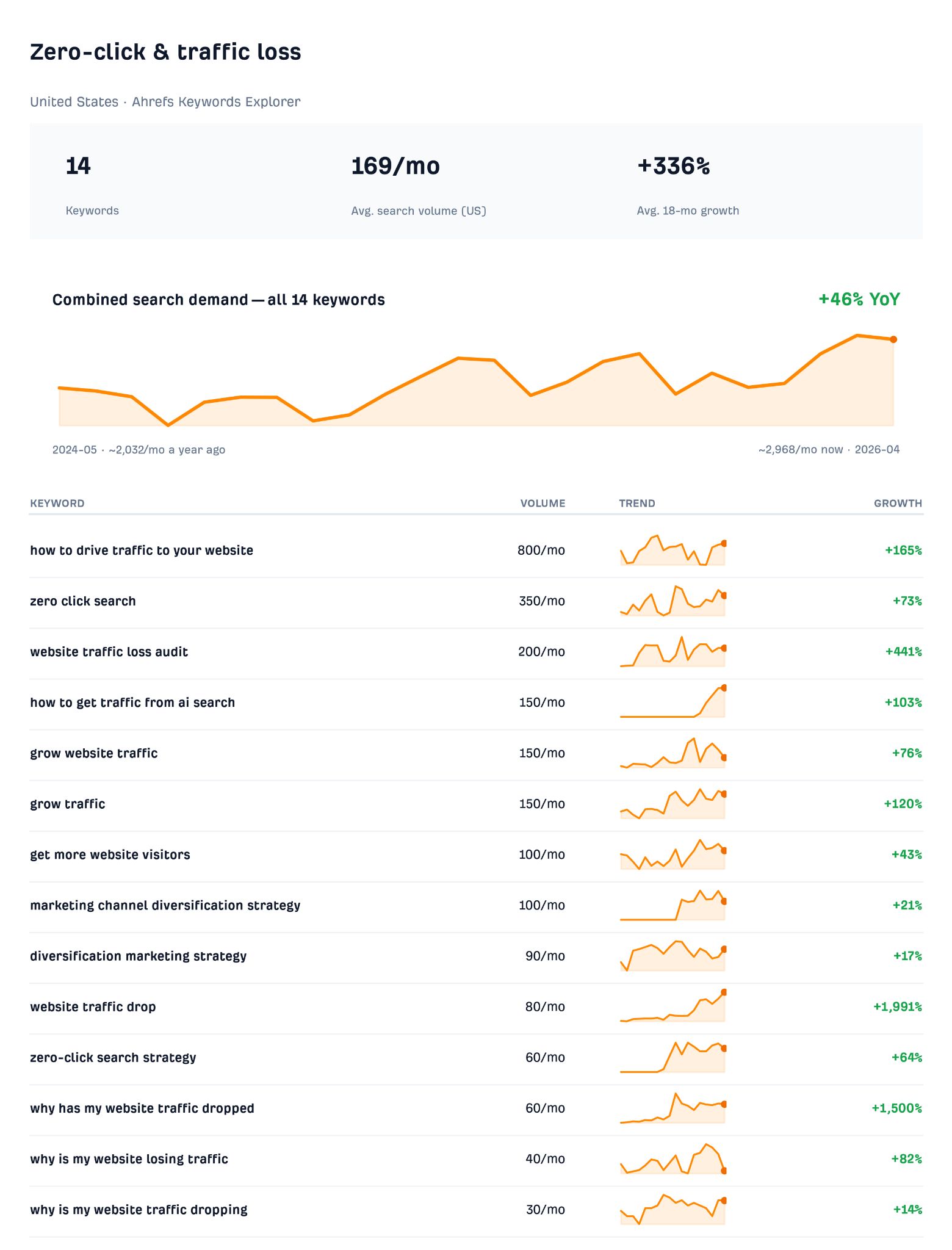
“Zero-click search strategy” US monthly search volume. Source: Ahrefs Keywords Explorer.
The one-way deal where Google takes your content for AI answers and returns less traffic is now being contested in regulators and courts.
Strategy SEO Lead, Chloe Smith, noticed that Google’s new Generative AI report in Search Console landed the same morning the UK’s Competition and Markets Authority outlined plans to challenge Google’s market status, including a requirement that Google give site owners a way to opt out of AI Overviews and AI Mode.
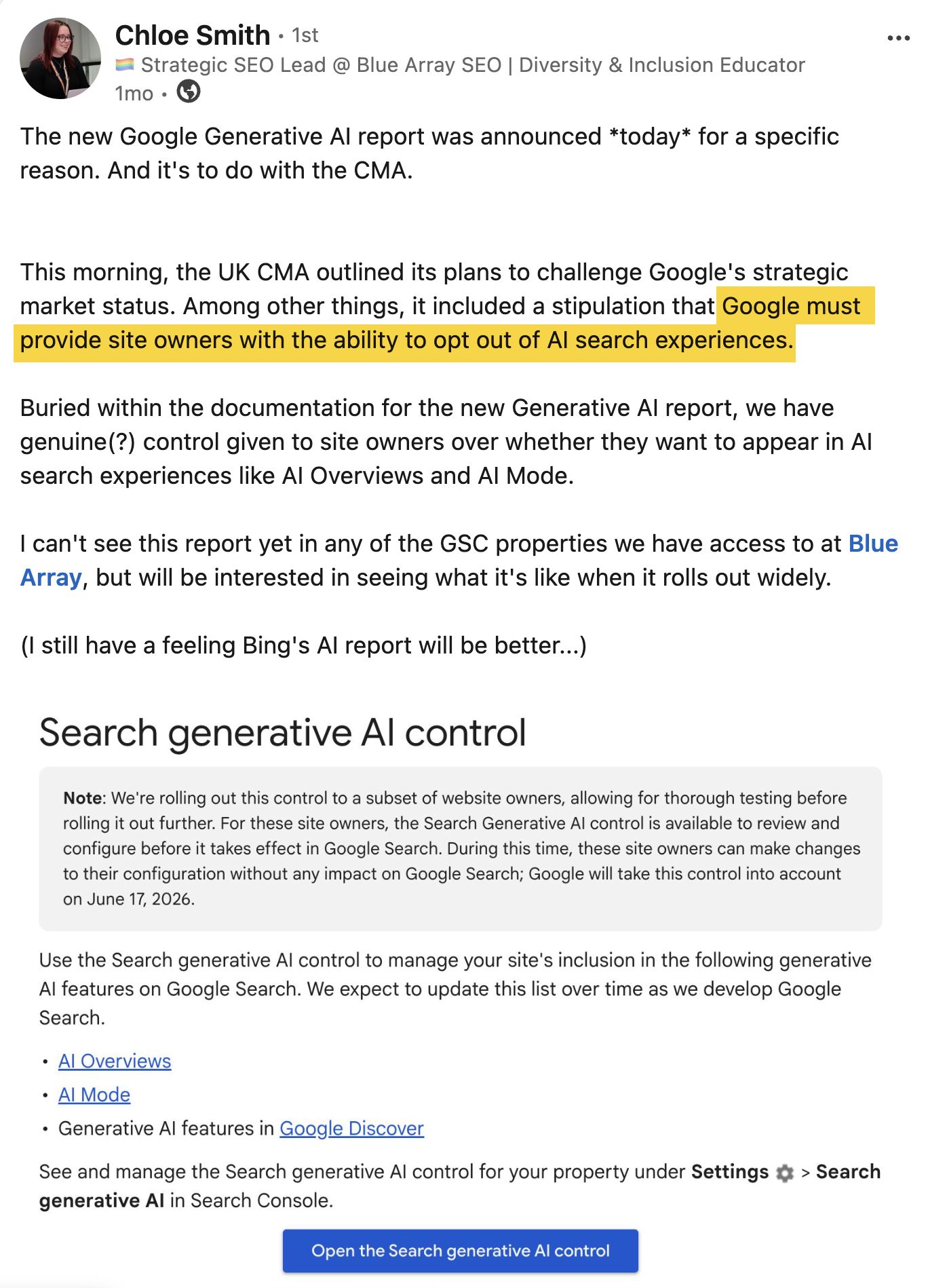
Google responded by developing a toggle option within Search Console, allowing users to dip out of AI search features.
But many are reading this as a response to regulatory pressure rather than a gift.
And we all have the same problem: opting out of AI search means opting out of potential traffic—though no one knows how much traffic, since Google still withholds that data.
According to our own estimates AI Overviews result in a click loss of ~58%.
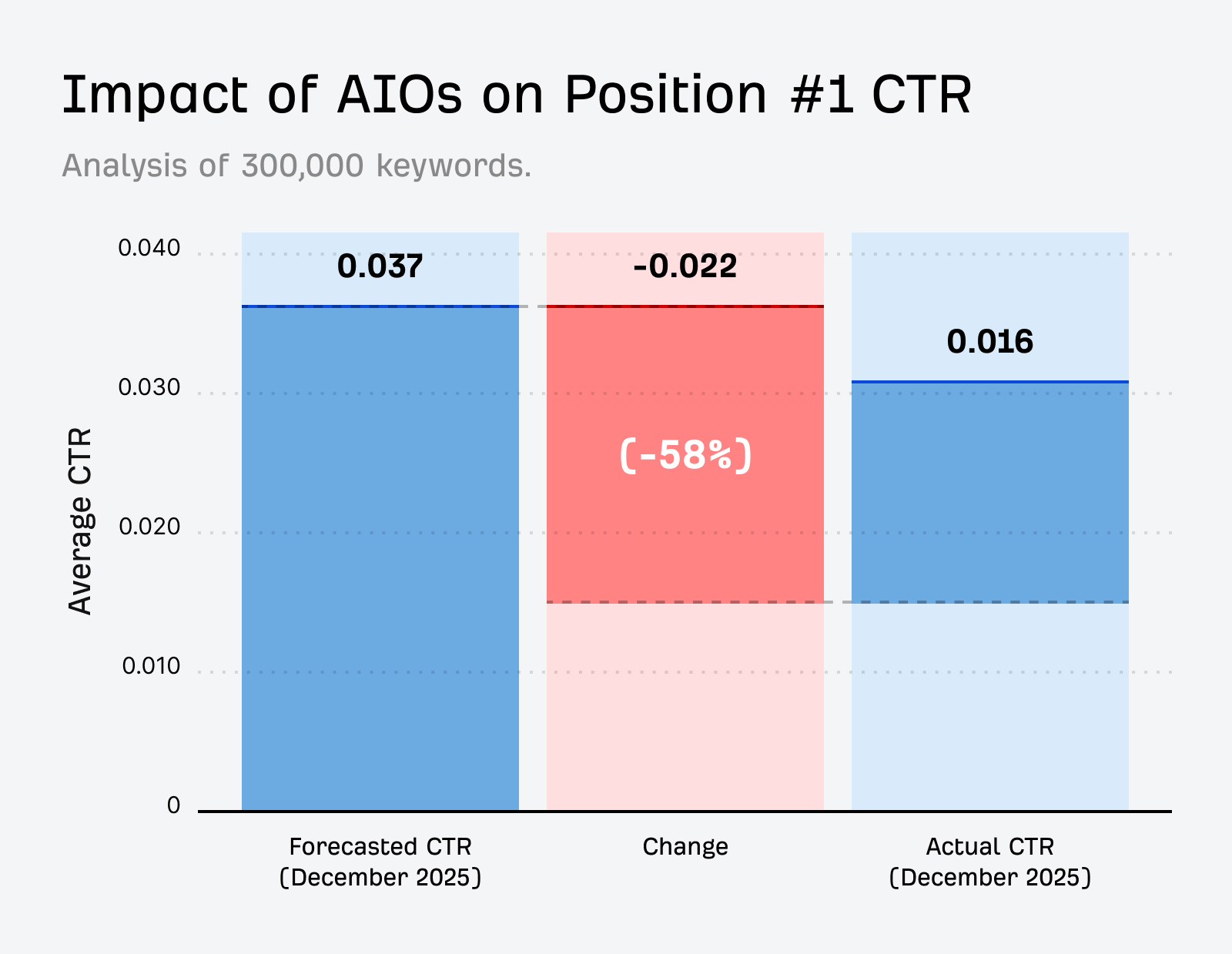
Most sites don’t see opting out as a real choice until CTR data—something which the CMA insists Google must provide—is incorporated.

While all of this was happening, another ruling was taking place—one which Insites CEO, Andrew Waite, argued deserved far more attention.
A Munich court ruled that AI Overviews are Google’s own words, not neutral search results, and now holds the company liable when one is wrong.
As Waite framed it, if Google wants to be the answer rather than the index that points to it, it has to own the answer—even when it is false.
Under his post Group Digital Marketing Manager at Belron, Chris Ellis, joked that the cookie banner may soon have a companion: an AI disclaimer users have to accept before reading a generated answer.
All of this news paints a slightly more positive picture for our organic traffic.
Google is getting duly taken to task on its use of AI to intercept our website clicks.
But while all of this plays out, we are still working out what to do about that dwindling traffic; from diagnosing how much we’ve lost, to seeking out strategies—like “marketing channel diversification”—to recover our losses.
To size up your own losses, Site Explorer’s traffic history, or Search Console data within Ahrefs, shows which of your pages have shed the most organic traffic.
The pattern to look for is the “crocodile mouth”: pages whose rankings/impressions held steady while clicks fell away.
That’s the signature of an AI Overview absorbing your clicks rather than a ranking problem.
![]()
![]()
Those pages are your starting point for recovery, whether that’s updating them, rebuilding them around queries AI can’t fully answer, or repurposing them for other channels.
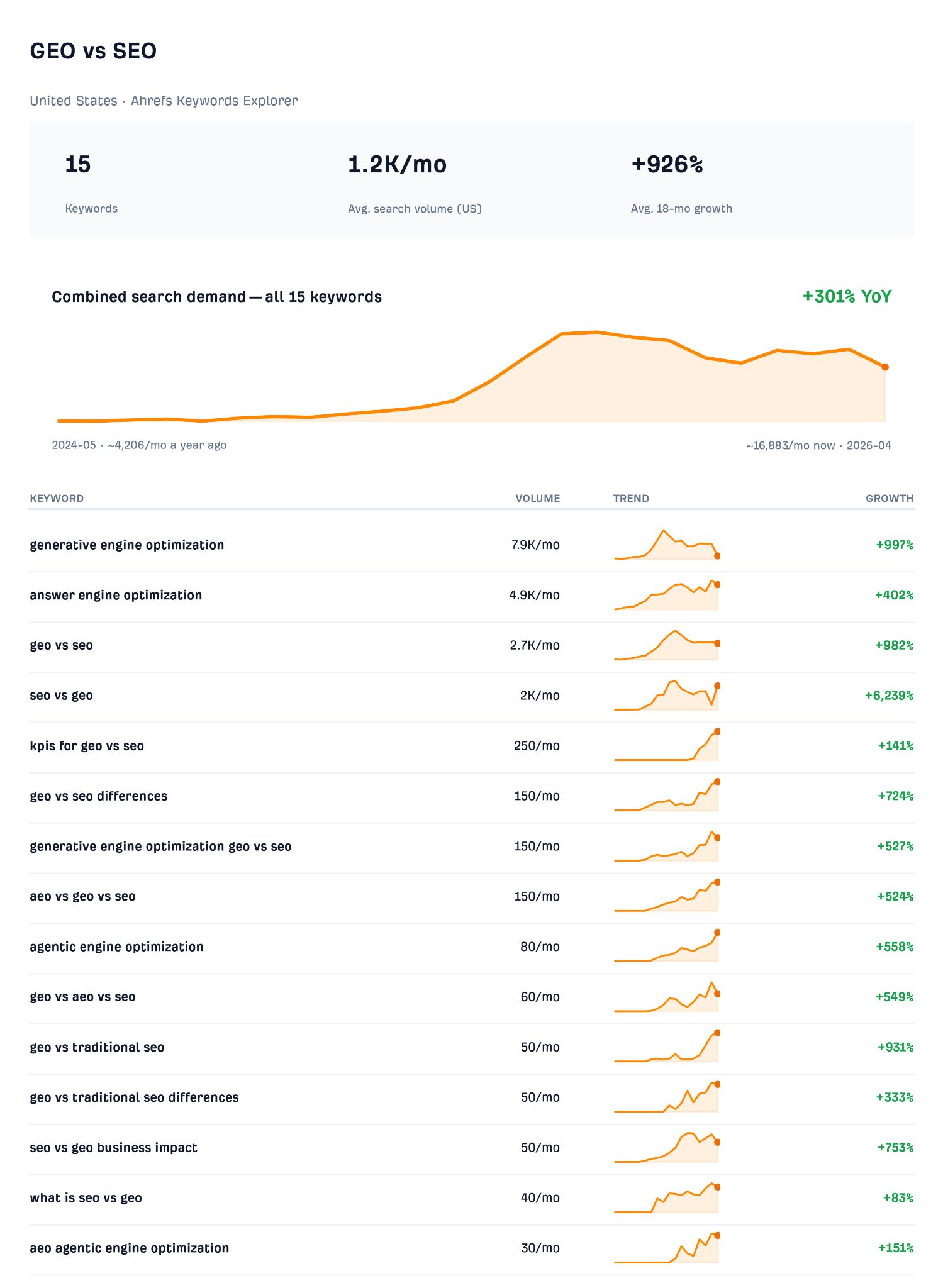
Thought you’d heard the end of the GEO vs SEO debate? Think again.
Marketers still can’t agree on what to call the work of getting found in AI, or how to define it, and over the past year the vocabulary has splintered further.
For instance, Director at Google Cloud AI, Addy Osmani, has given AEO a second meaning, shifting it from “Answer Engine Optimization” to “Agentic Engine Optimization”.
That phrase is now a breakout keyword at 80 monthly searches.
Whatever you call it and however you define it, search volume for this cluster is climbing across the board, with “generative engine optimization” up 997% over the last 18 months, “geo vs seo” up 982%, and a whole bunch of vs-comparisons that barely registered last year now pulling in real volume.
On r/SEO, one widely-read thread asks: is AEO actually replacing traditional SEO, or is it just hype?
Over in r/content_marketing, the answer that generated a lot of discussion was that AEO and GEO are not killing SEO, but repackaging it.

AI SEO Researcher at Snippet Digital, Suganthan Mohanadasan, argues that the “newness” of GEO is in the protocols, not in renaming the fundamentals.
While skeptics like Jan-Willem Bobbink believe that “GEO tactics” simply don’t work.
He told of a study that ran a page through a typical GEO checklist; adding statistics, quotations, source citations, and an authoritative tone, across three AI engines.
On GPT-4o-mini the untouched page got cited 13.3% of the time. The same page after the full GEO treatment landed lower, between 10.9% and 12.2%.
In Jan-Willem’s words, the tactics everyone is selling “lost to doing nothing at all.”
In the grand scheme of things, AI search is still a relatively new discipline.
As long as marketers continue testing out novel and traditional strategies to boost their AI visibility, the SEO vs GEO war will wage on.
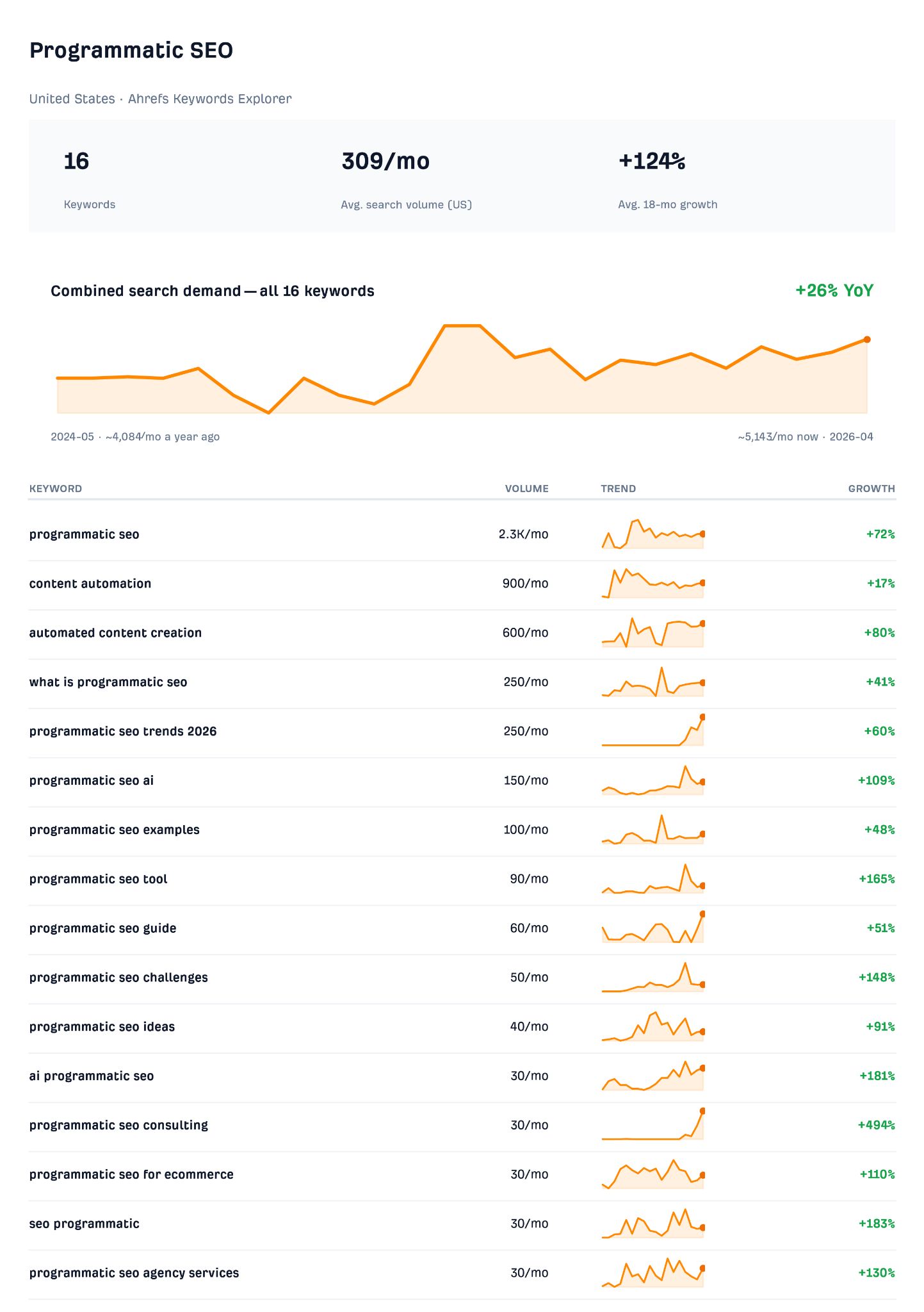
Programmatic SEO is hardly a new strategy, but AI has breathed life back into it.
Now that anyone can generate scaled content in fraction of the time, at a fraction of the cost, programmatic strategies are being embraced like never before.
Search volume for the term itself is up 124% over 18 months, and the surrounding cluster—“content automation,” “automated content creation,” “programmatic seo ai”—is climbing alongside it, with combined demand up 26% year-on-year.
This isn’t the strongest of all search trends on our list but, anecdotally, I am seeing discussions about programmatic content everywhere on social media right now.
Most of the current attention, though, comes from people warning each other off it.
Google’s recent crackdown on content built for scale rather than users (including the March and June Spam Updates) has prompted a run of cautionary posts on LinkedIn.
Fractional VP of Marketing, Lars Lofgren, has begged people to stop doing programmatic SEO, pointing to company after company whose rankings got demolished once they scaled into the thousands of pages.

Founder of Algorythmic, Lily Ray, has seen the same thing: certain page types become a liability rather than an asset at scale, and she’s traced over 70 companies penalized in Google’s early 2026 algorithm updates alone.
But not everyone agrees that programmatic SEO is an out-and-out bad thing.
In his article “The Free Tools SEO Strategy: How to Rank With Calculators, Converters, and Generators” Ahrefs Director of Content, Ryan Law, makes the case for scaling something other than written content: tools pages.
Our free tools consistently rank among our highest-traffic pages, holding steady even as AI answers eat into click-through rates.
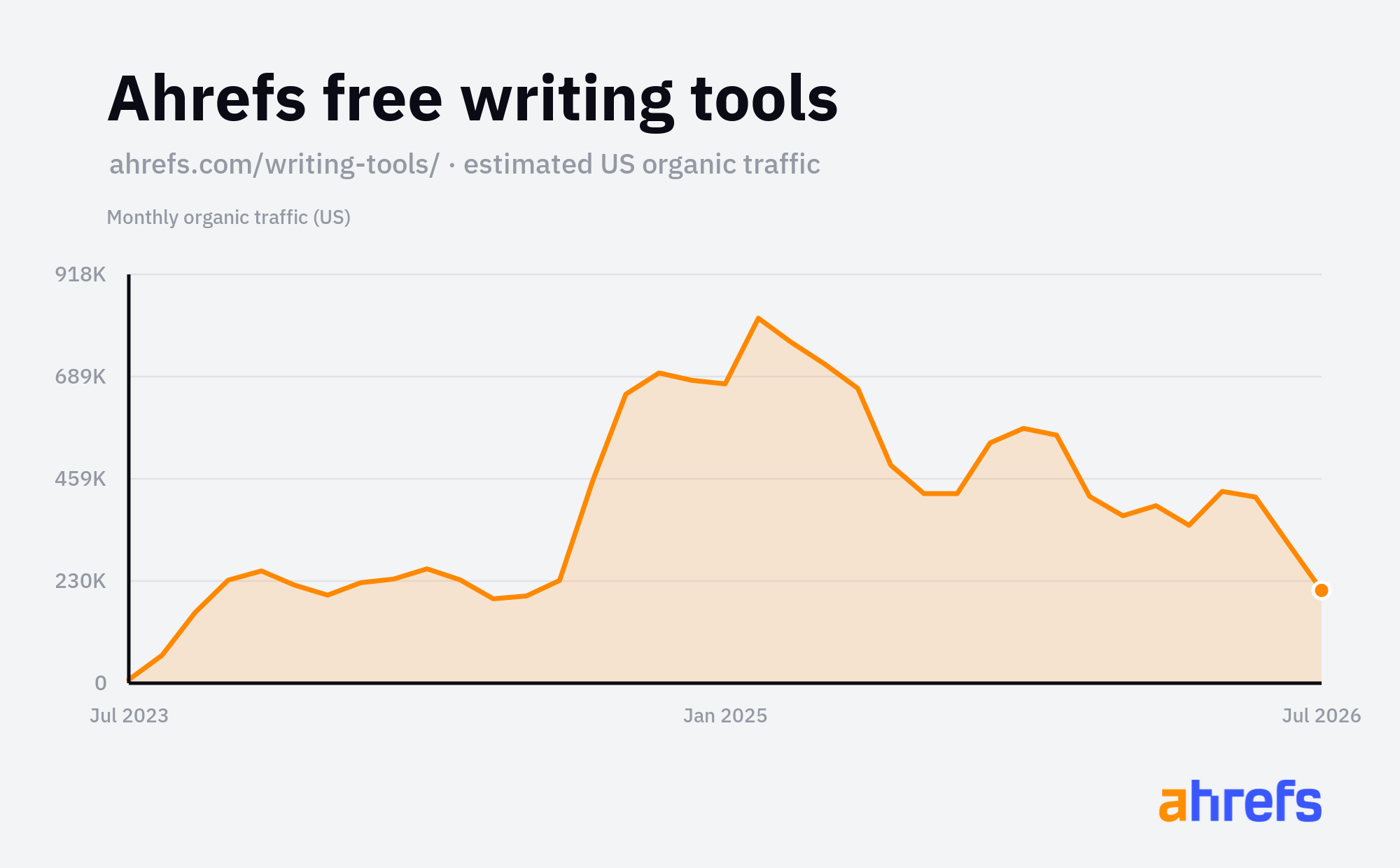
As Ryan says, searchers want to do, not read, and a tool is much harder for Google to summarize out of existence.
I can’t see interest in this trend dropping off any time soon.
AI has made scaled content cheap enough that everyone will keep trying it—some carefully, some not—and both the success stories and the horror stories will keep feeding the conversation.
Final thoughts
If there’s a thread running through all five trends, it’s that marketers want proof.
Proof that citations convert, that agents can parse a page, that scaled content won’t blow up the domain.
Every one of these trends started as a Slack message, Reddit discussion, or LinkedIn comment thread, then became its own search cluster.
Whatever niche topics are showing up in those spaces now is probably next year’s trend, so my advice would be to watch them closely.
Free LLMs.txt Generator
Enter your domain and our free generator will build the perfect llms.txt file for you in seconds.
Our free llms.txt generator is based on detailed analysis of 137,000 domains. Share this free tool with your boss, your colleagues, your clients, your GEO agency, or anyone who recommends you use an llms.txt file.
4 Pillars to Show Up More (and Right) in AI Answers
AI search probably won’t replace all the organic traffic websites are losing to AI. But traffic is only one piece of the puzzle.
Before someone ever lands on your website, an AI assistant may have already explained what your product does, compared it with competitors, and helped them decide whether you’re worth considering. By the time someone clicks through to your site after a conversation with an AI assistant, they may already understand the market and know exactly what they’re looking for.
That’s the real opportunity. Instead of focusing only on clicks, focus on becoming a brand that AI can accurately describe and confidently recommend.
To make that happen, focus on four things:
- Give AI a clear, reliable source of truth about your business.
- Build third-party evidence that shows your brand belongs in the category.
- Publish content that remains valuable even after AI summarizes it.
- Track your AI visibility over time to see what is improving.
In this article, I’ll walk you through each of these areas and show you how to improve your visibility in AI search.
Think of an AI assistant as a new salesperson learning about your product from the public web. It needs clear answers to a few basic questions:
- What does the product do?
- Who is it for?
- Which problems does it solve?
- How is it different from competitors?
- What does it cost?
- Which tools does it integrate with?
- Where should a new customer start?
If those answers are scattered across landing pages with incomplete information, outdated blog posts, and stale profiles, the AI fills in the gaps. That’s how it ends up repeating old messaging, recommending your product to the wrong audience, or getting key details wrong.
To show you what I mean, here’s a real example of what happens when AI runs into a documentation gap. It correctly recognized that Ahrefs Brand Radar has a free demo version, but because it couldn’t find clear documentation, it conflated the functionality of the demo version and the paid version.
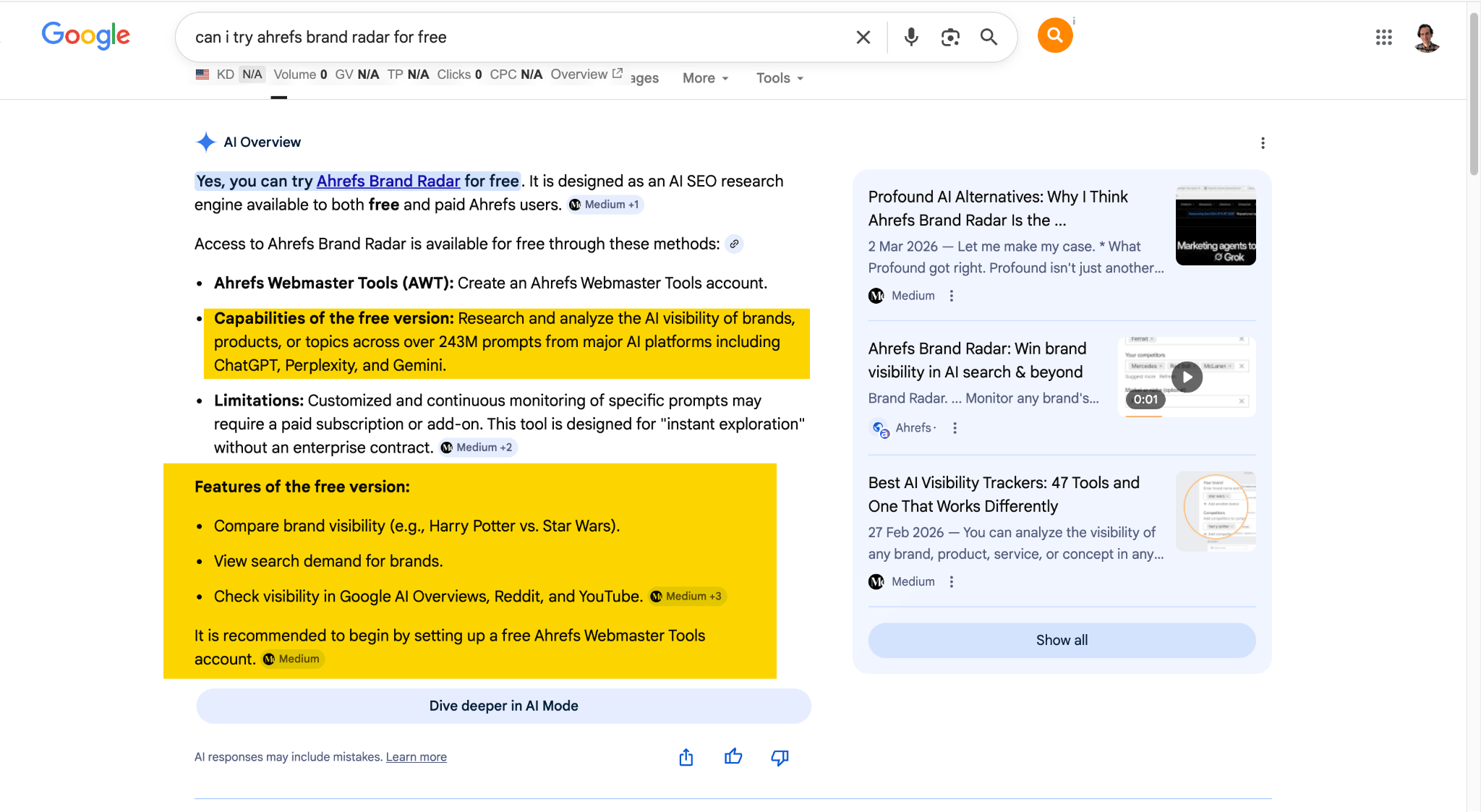
This is one of the clearest differences between GEO (Generative Engine Optimization) and traditional SEO. In SEO, we usually create pages to rank for specific queries. In GEO, some pages are valuable even if they never rank because they give AI systems a dependable source of truth.
If you look at a big tech brand like Samsung, you’ll see that their most valuable pages look like something a Sales or Support rep could use when chatting with customers (product guides, support docs, FAQs, etc.). Documentation for features, integrations, pricing, use cases, and product terminology helps AI answer questions accurately, and that is its new role.
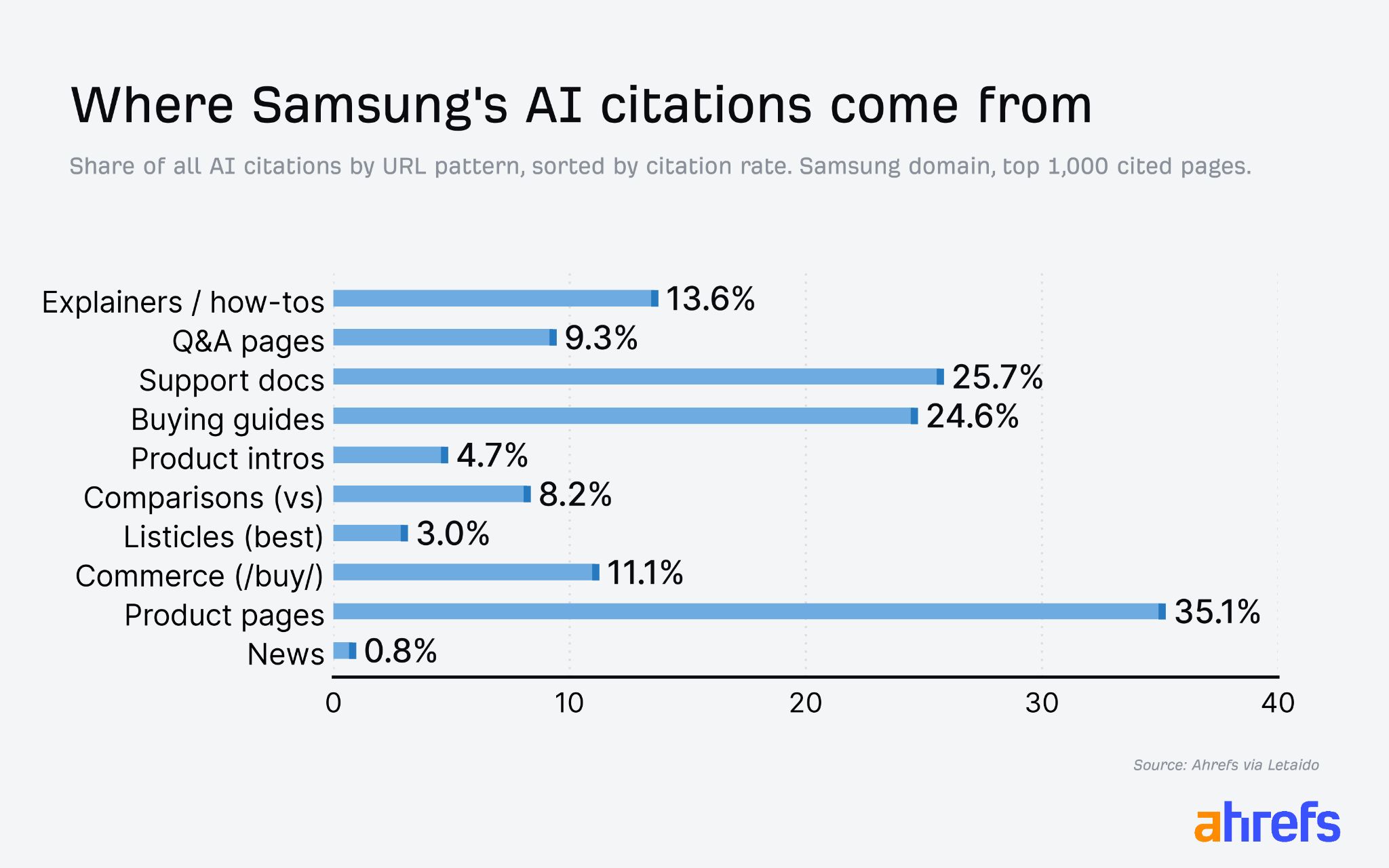
What’s more, your documentation extends beyond your website. It includes every profile you control on platforms like G2, Capterra, LinkedIn, Crunchbase, app marketplaces, and partner directories. AI assistants frequently use these pages, and they’re often the first place your messaging becomes outdated.
Do a quick test: take any brand and ask ChatGPT whether it’s trustworthy. I think you’ll find these sites influence the answer:
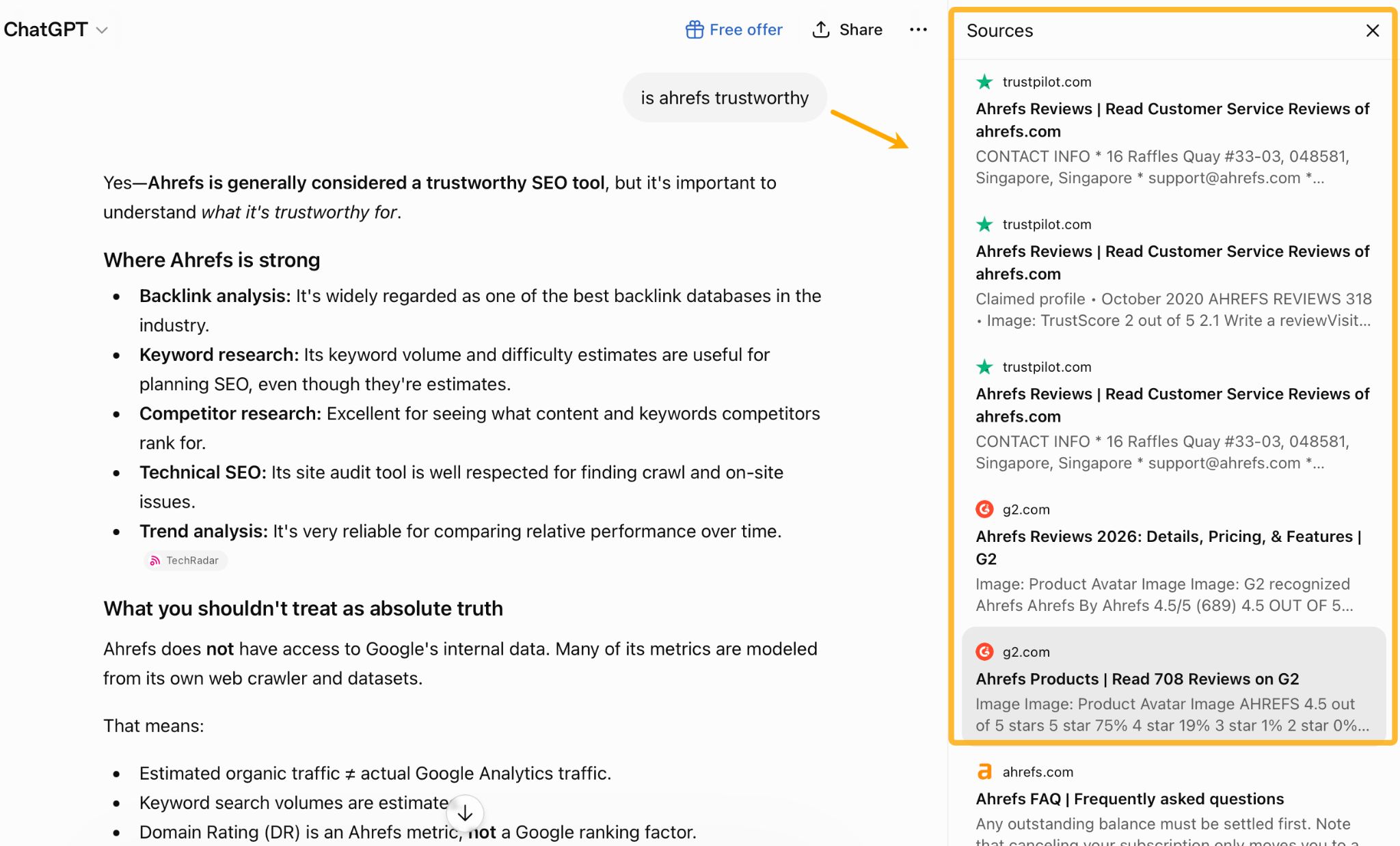
If you want to optimize for AI search, treat every owned profile as part of your source of truth. Keep your descriptions, positioning, pricing, and product details consistent everywhere.
Whenever possible, back up your claims with evidence—reviews, certifications, rankings, or awards. The more signals AI can cross-check, the more confident it can be in describing your business accurately.
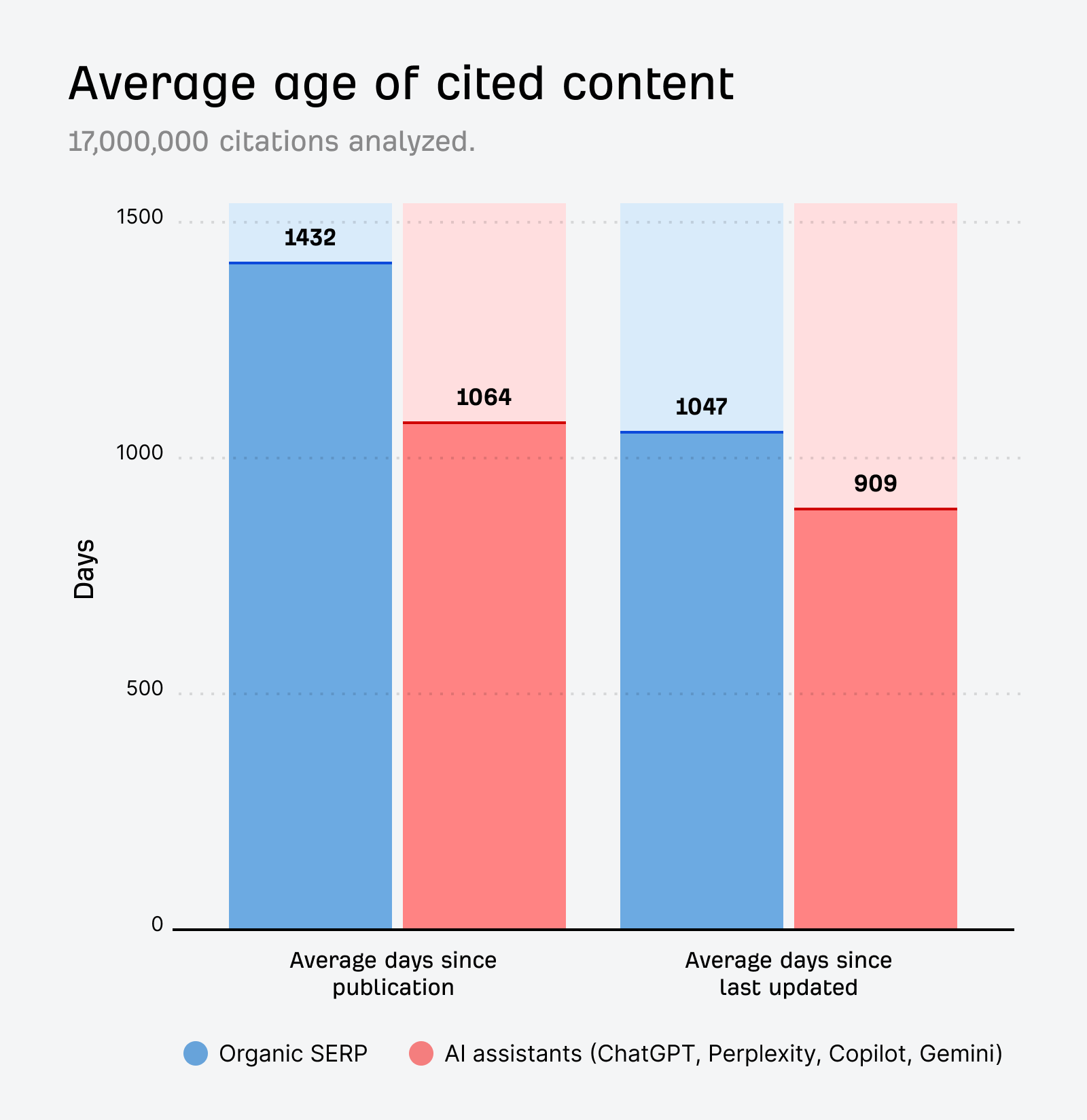
Don’t forget to keep your claims up to date. Our research found that AI assistants favor fresh information: AI-cited content is 25.7% fresher than organic Google results.
How to get started
Reviewing every page and profile you own can quickly become overwhelming. But you can uncover most issues with these three checks:
- Review the branded profiles you control (G2, LinkedIn, Google Business Profile, Facebook, YouTube, and others).
- Check whether your pages ranking for branded searches are accurate and up to date.
- Ask AI assistants specific questions about your brand and products to uncover gaps in your documentation.
The first one is fairly straightforward, so let’s focus on the other two.
You can see which of your pages AI cites, which ones AI bots visit, and when they were last updated with Ahrefs Brand Radar. Just create a report, enter your brand name and domain, open the Cited pages report, and switch to the Yours tab.
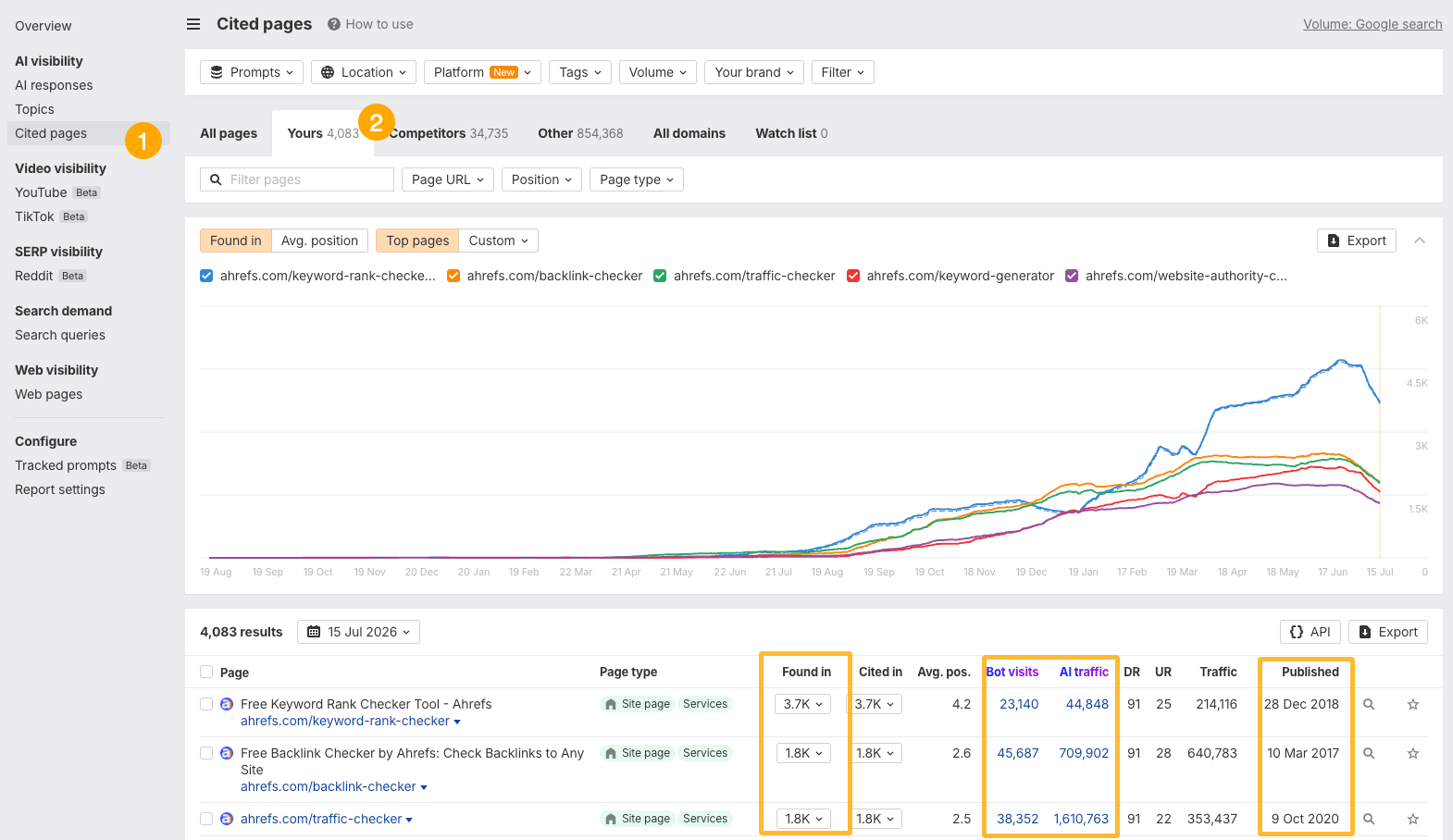
To see AI bot activity and AI search traffic, you’ll first need to set up Ahrefs Web Analytics (it’s free). Once data starts coming in, you’ll see Bot visits and AI traffic columns in the report.
Recommendation
If you want to analyze citation freshness across a large website, try the Letaido skill I built. It looks for signals that indicate when a page was published or last updated, making it easier to audit large, complex sites. It also includes filters designed specifically for this workflow.
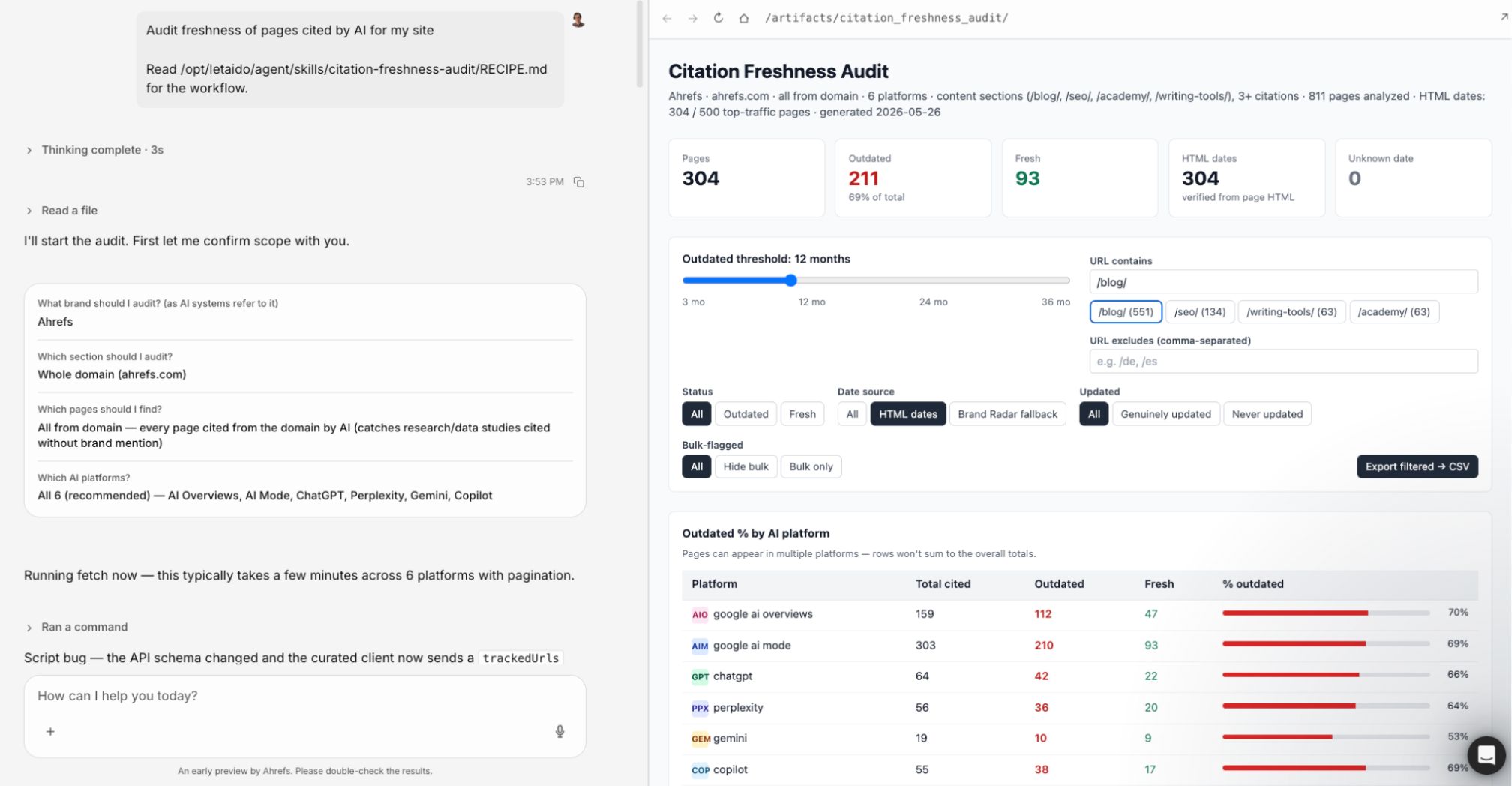
The third method is to ask AI assistants directly. You can do this manually in ChatGPT, Claude, Gemini, or any other major chatbot.
If you have an Ahrefs subscription, you can also automate this with custom prompts, so you can track answers over time without leaving Brand Radar.
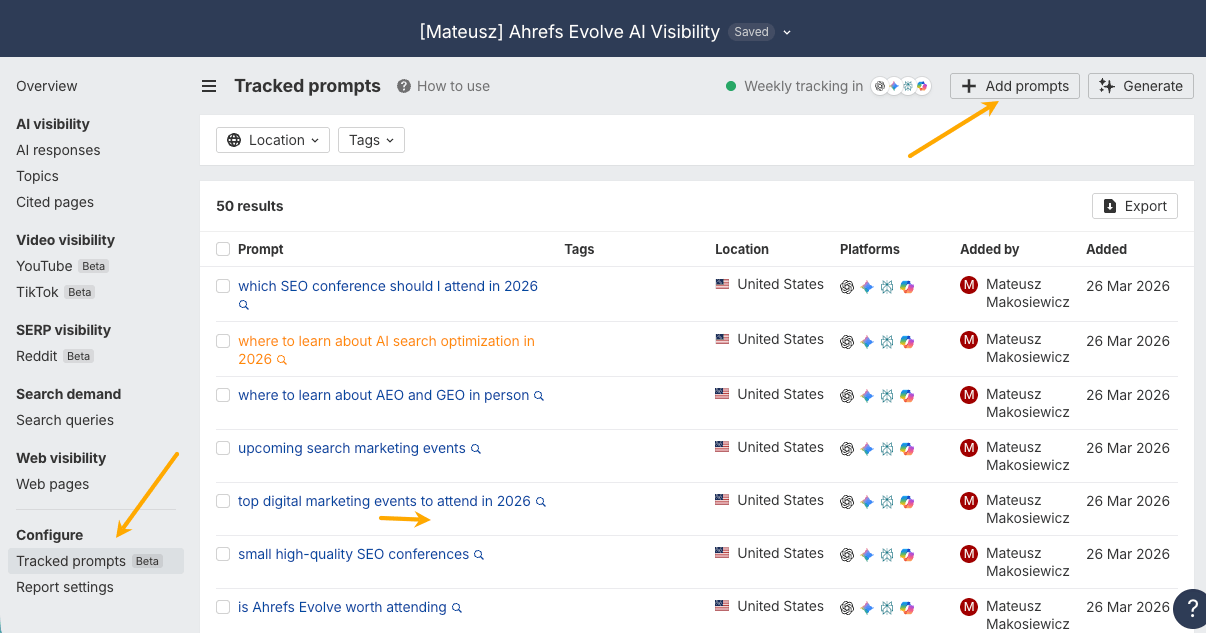
For example, on the Standard plan, you can track up to 37 custom prompts across ChatGPT and Gemini each week (or switch to daily tracking). This helps you distinguish one-off mistakes from recurring issues and see whether answers improve after you publish new content.
When setting up your prompts for tracking, think like a potential customer. Sales calls and support conversations are great sources of ideas.
AI can also help you brainstorm. Try asking something like:
What questions might someone ask ChatGPT while researching my product? Learn about my product first from [your domain].
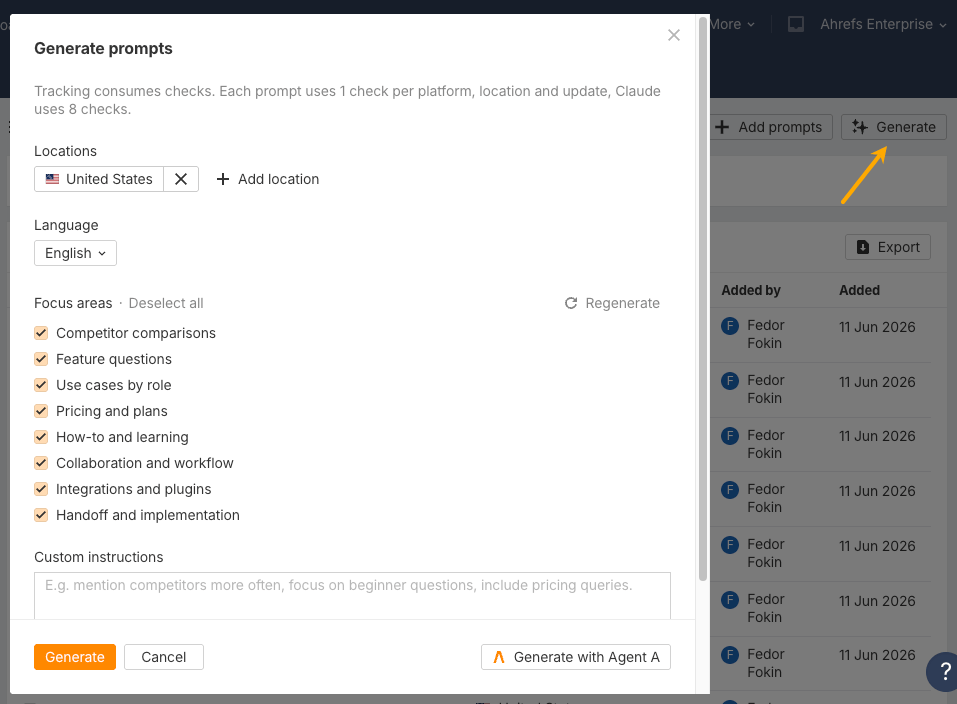
Or use the Generate prompts feature in Brand Radar to get started.
One more tip: pay attention to URLs that AI hallucinates. They often reveal pages that AI expects to exist but don’t. Those are good candidates for new redirects or even new content.
AI assistants do not learn about your brand only from your website. They also use reviews, YouTube videos, analyst coverage, industry publications, comparison pages, podcasts, Reddit, and customer discussions.
In fact, it is quite likely that your brand mentions in AI answers will come from third-party pages—that’s exactly the case with our brand.
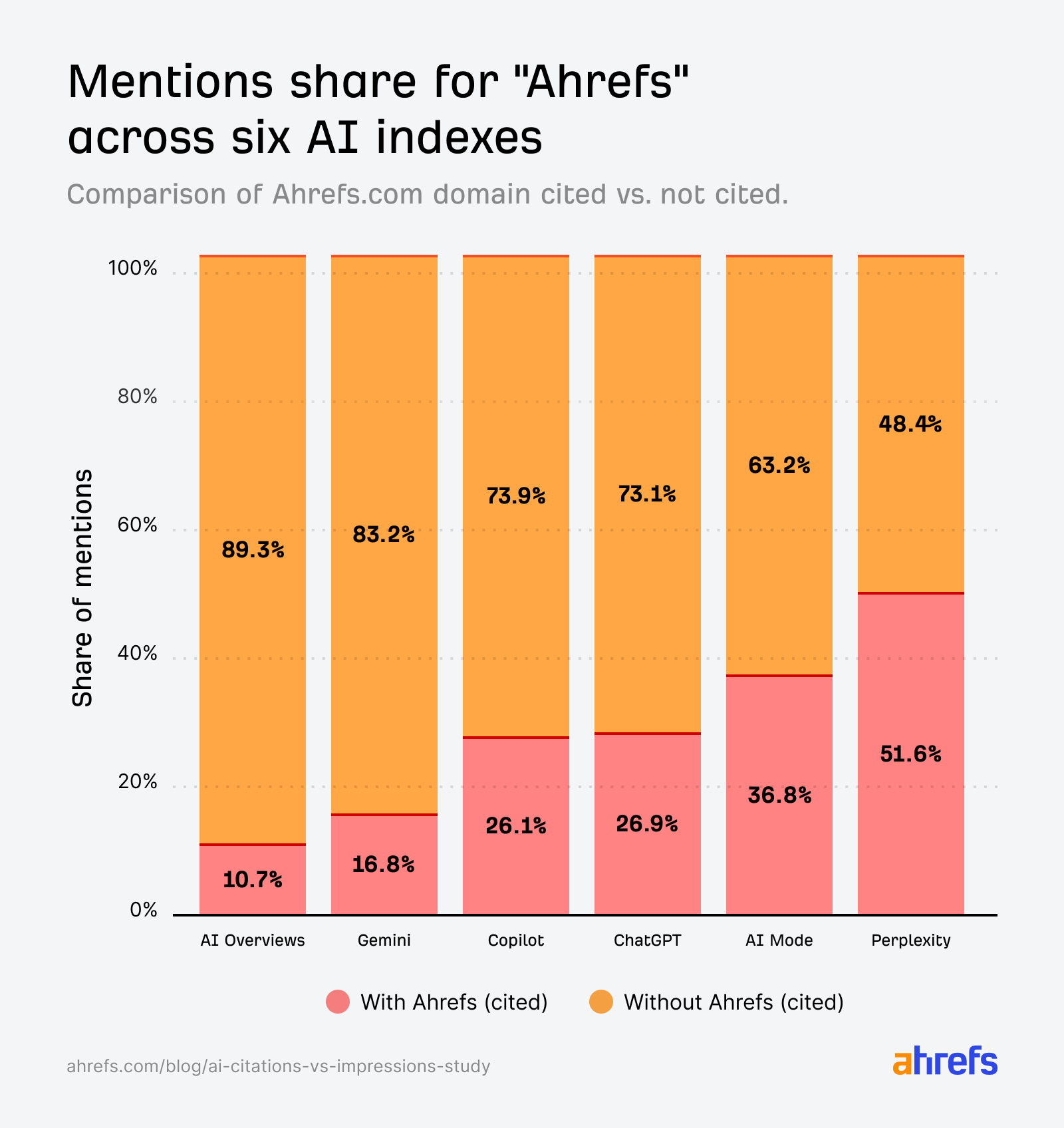
In most cases (up to 89%), the Ahrefs brand appeared in AI answers because other websites mentioned it, not because the AI relied on the brand’s own website. Data: Ahrefs Brand Radar.
When AI wants a more human perspective, it often turns to user-generated content. In our research, YouTube, Reddit, Facebook, and LinkedIn were among the most frequently cited platforms.
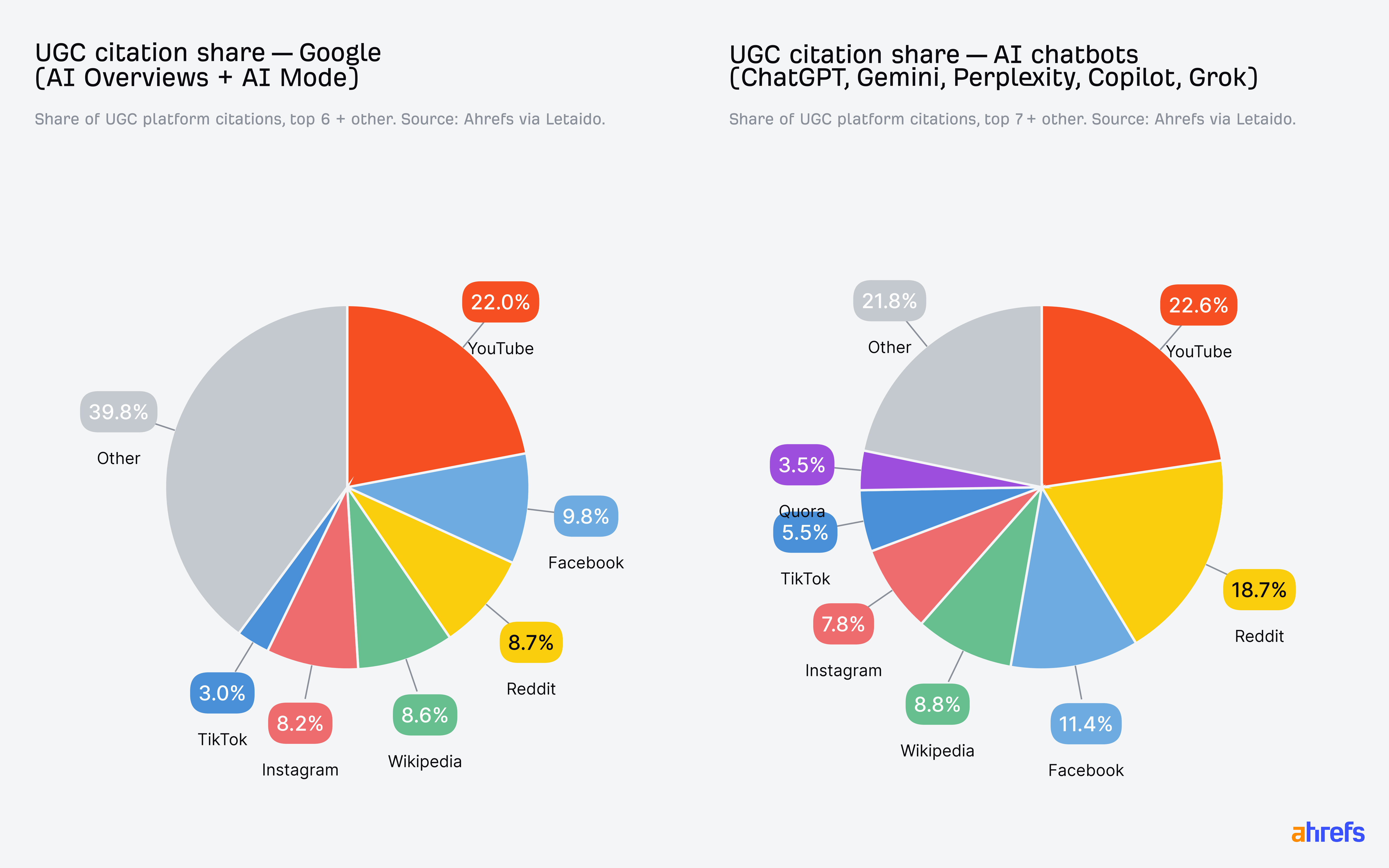
Together, your own content and third-party mentions shape AI’s understanding of your business. They create an online consensus about which brands belong in a category.
That’s important because AI assistants tend to recommend the same relatively small group of established companies. Those brands have spent years accumulating reviews, comparisons, media coverage, and customer discussions. AI largely reflects the consensus that’s already visible across the web.
We’ve seen this in our own research, and others have observed the same pattern.
For example, Ayomide Joseph tested how AI responded to different prompts asking for alternatives to three SaaS products. Even when he changed the wording of the questions, the same handful of brands appeared repeatedly. They were established companies with years of accumulated trust signals, no random recommendations.
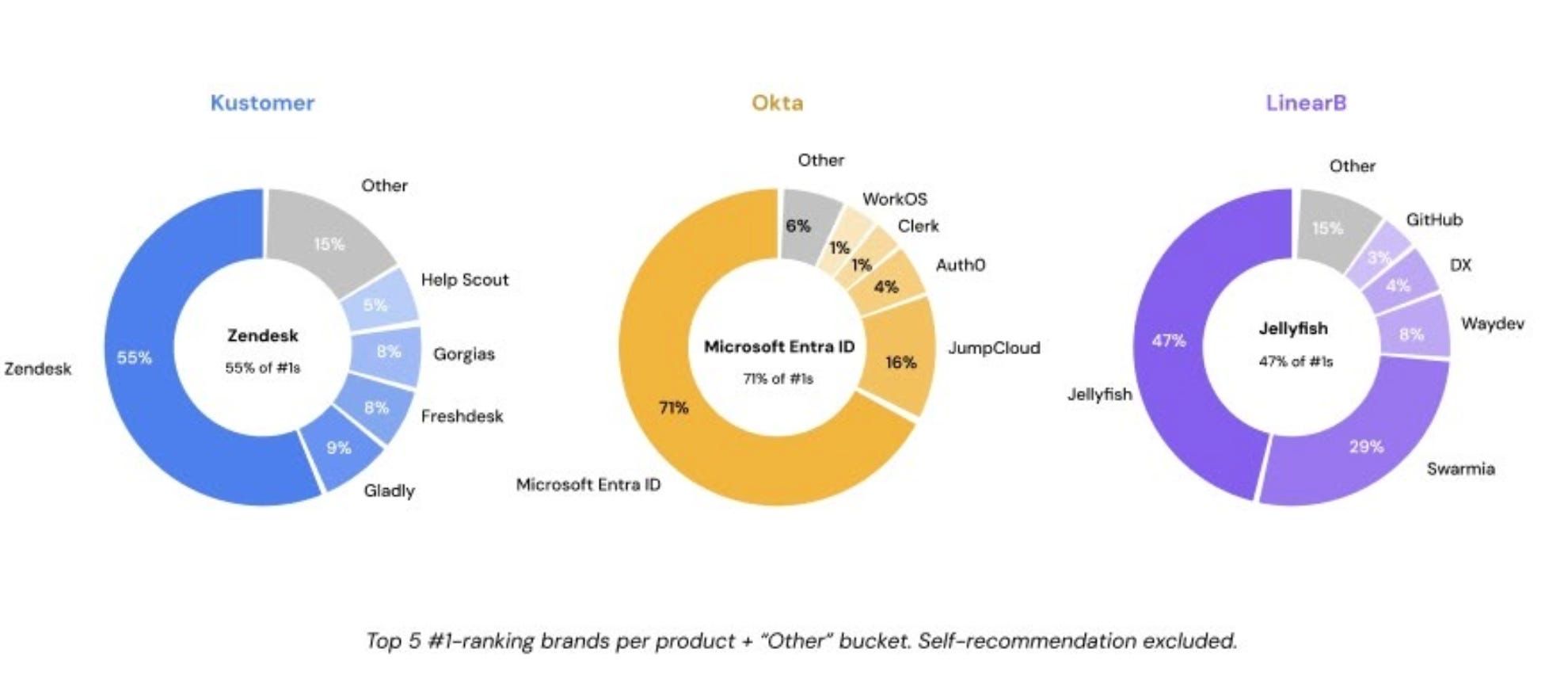
This also helps explain why similar pieces of content can produce very different results. One brand earns citations while another doesn’t—not because the content is dramatically better, but because AI has much more evidence that the first brand belongs in the conversation. J.H. Sherck and Kevin Indig have reported similar findings.
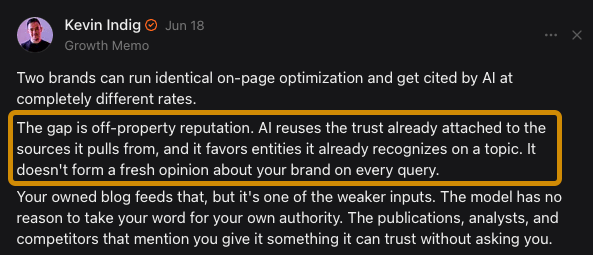
Moreover, our study of 75,000 brands found that off-site mentions, especially the ones from YouTube video transcripts, had some of the strongest correlations with visibility in ChatGPT, Google AI Mode, and Google AI Overviews.
So before AI decides whether to recommend you, it first needs enough evidence to include you in the category at all.
The most useful mentions consistently connect your brand with:
- The right category—for example, “Ahrefs is an SEO platform,” not just “a popular tool”
- The problems you solve—“we used Ahrefs to figure out why our traffic dropped”
- The customers you serve—“a favorite among in-house SEO teams and agencies”
- The use cases you want to own—“the go-to for backlink analysis and keyword research”
- The competitors buyers compare you with—showing up in “Ahrefs vs. Semrush” comparisons, not against tools you’ve outgrown
This is why you need a source strategy, not just a content strategy.
Focus on places AI systems already use to generate the answers:
- User-generated content platforms, especially YouTube, Reddit, Facebook, and LinkedIn
- Industry publications and analyst sites
- G2, Capterra, and other review platforms
- Partner marketplaces and integration pages
- Third-party listicles and comparison pages
In the next section, I’ll show you how to check which exact pages influence the category in your case.
How to get started
Start by checking whether AI assistants already include your brand among the companies they regularly recommend in your category.
If they do, focus on protecting that position and making sure AI describes your business accurately.
If they don’t, you’ll need more third-party evidence that connects your brand with the category, the use cases you want to own, and the competitors you want to be compared against.
For example, if I wanted to check Ahrefs’ visibility in the SEO tools category, I’d create a Brand Radar report and enter “SEO tools” as the category.
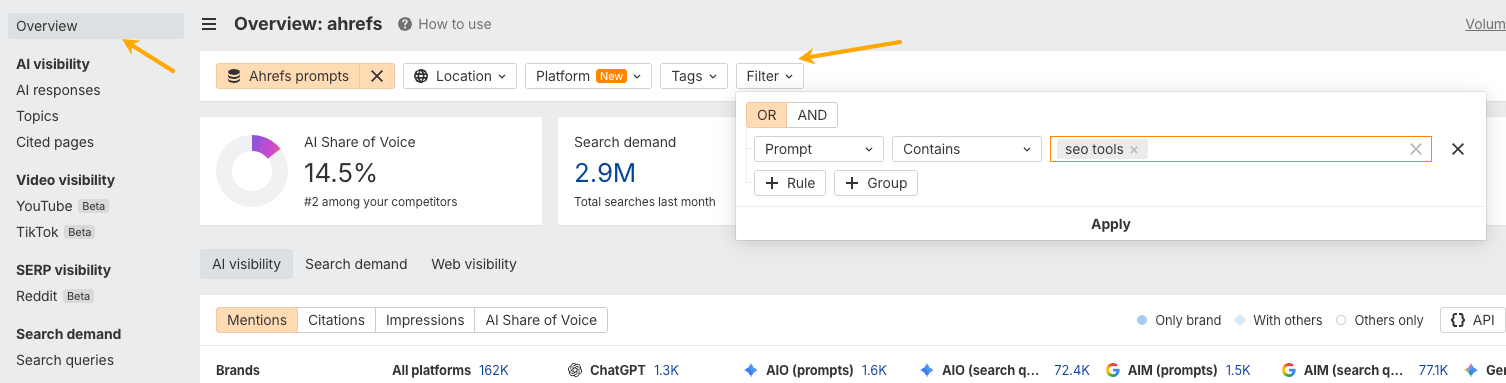
In that category, Ahrefs has an AI share of voice of 87%, making it highly likely we’ll be mentioned in conversations about SEO tools.
To find the gaps, I’d hover over the Ahrefs brand name in the AI visibility breakdown chart and select Others only.
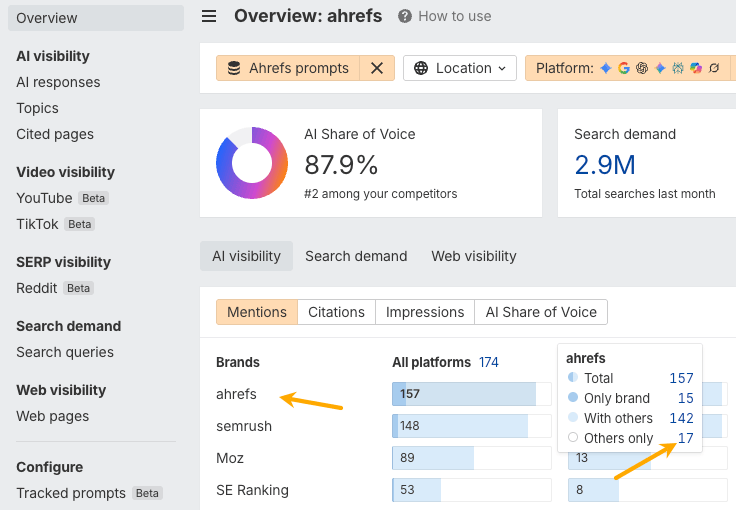
This filters the report to prompts where competitors were mentioned, but Ahrefs wasn’t.
For example, I can see that Ahrefs wasn’t mentioned in responses to “Which SEO tools are best for beginners?” in Google AI Mode and AI Overviews in the US.
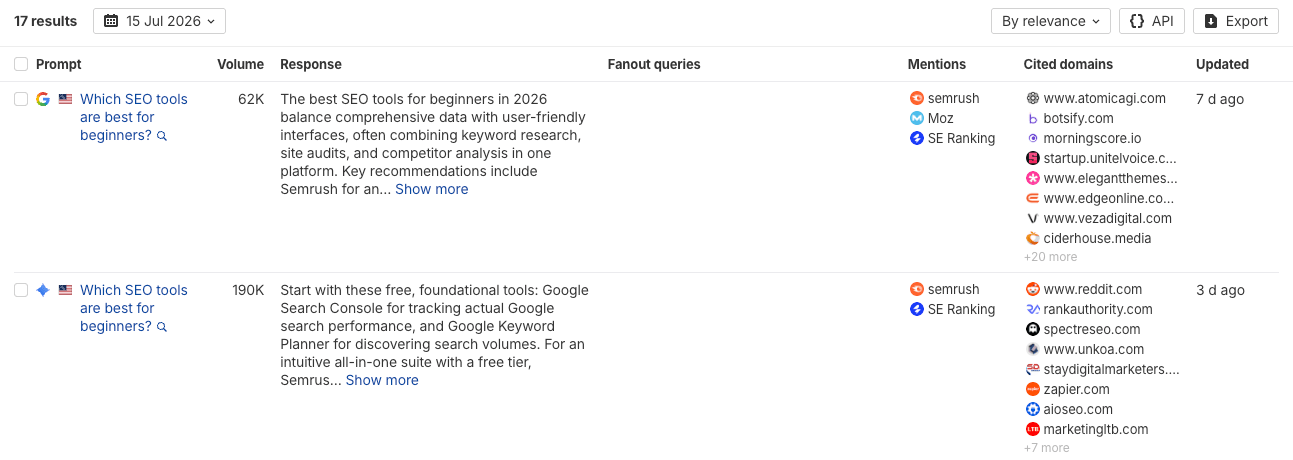
The next step is to understand why.
I’d open those AI answers, review the pages they cite, and look for opportunities to earn mentions on those sites. At the same time, I’d consider whether our own website should do a better job covering the topic. In this example, creating a page about why Ahrefs is a good choice for beginners could strengthen the evidence AI finds.
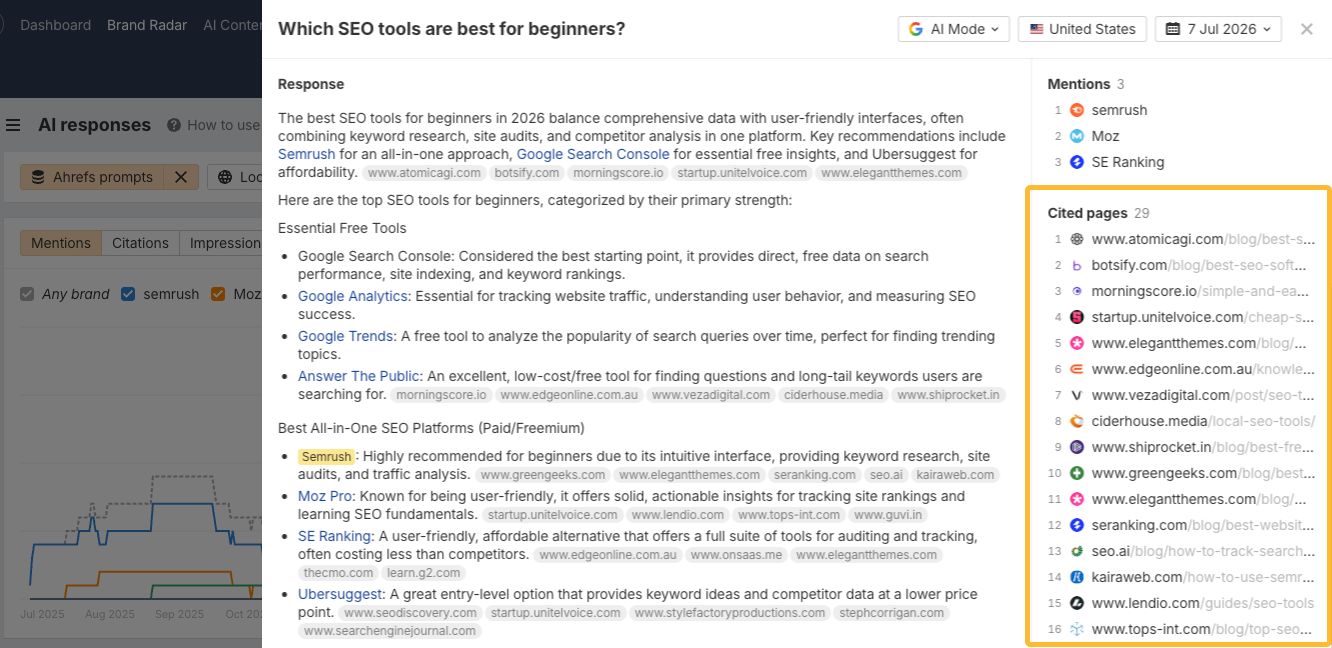
There’s also a faster way to identify these opportunities.
With the same filters applied, open the Cited pages report and look at the Mentions on page column.
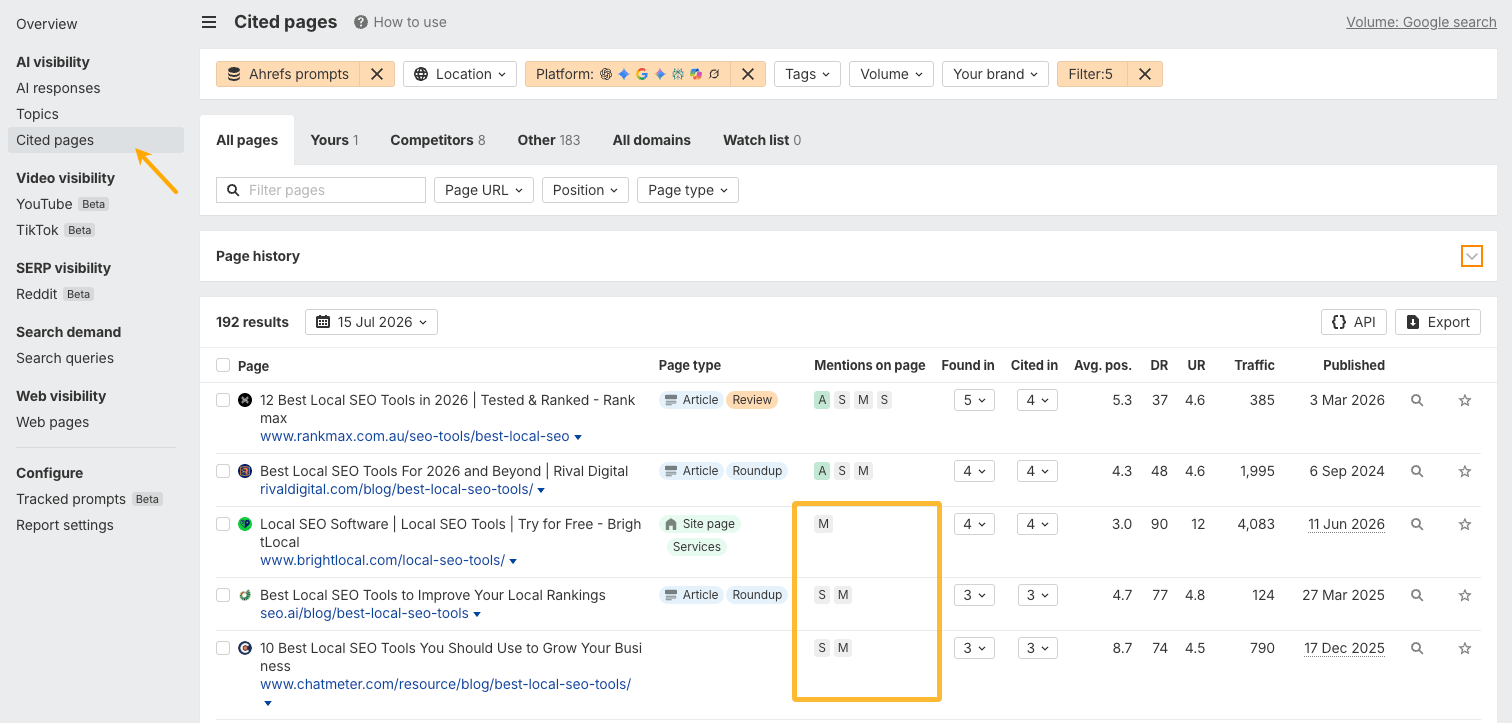
This gives you a list of pages that influence AI answers but don’t mention your brand.
Use it to prioritize outreach, partnerships, creator collaborations, reviews, and community participation. Focus on the sources that have the greatest influence on AI answers in your category.
If you don’t see enough prompts related to your niche in the main AI Index, create your own with the Custom prompts feature.
When someone asks AI a question, it summarizes the best available sources. Clicking through to those sources is optional.
That raises a simple question for every topic you publish: if AI summarizes this page, what’s left for someone to click on?
Basic explainers, generic how-to guides, and trend recaps rarely leave much behind. AI can summarize them without losing much value.
The content that holds up falls into two categories:
- Content that keeps its value after summarization
- Content that resists summarization.
Original research, firsthand experiments, and original opinions keep their value—they belong to the first category. AI can quote a statistic or summarize a finding, but it still needs to credit the source. That attribution builds awareness and authority—and often sends people back to the original article. Joshua Hardwick predicted this back in 2024 with his “deep content” idea.
That’s exactly what we’ve seen at Ahrefs. Thousands of AI citations come from our original research because it offers something AI can’t find elsewhere.
In fact, with content like that, AI can even encourage the user to visit the page for the full story.
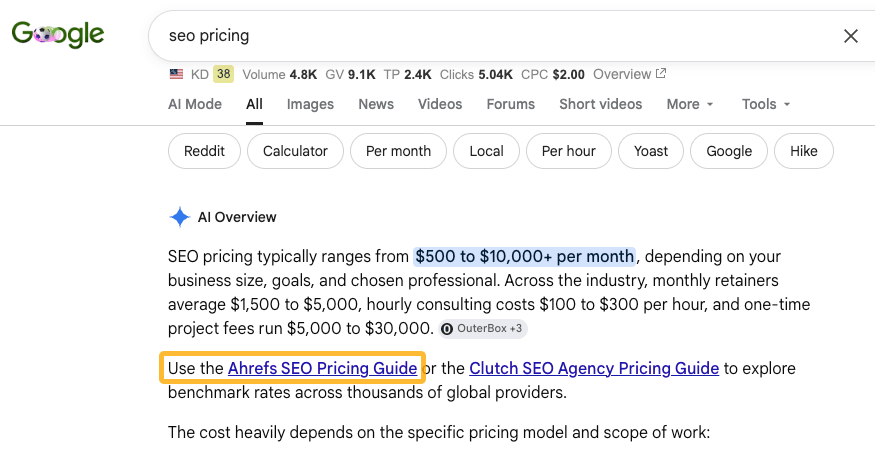
These are topics where AI can explain what to do, but not how to do it. Ask ChatGPT how to run a content audit, and you’ll get a solid outline, but the hard decisions are still yours to make.
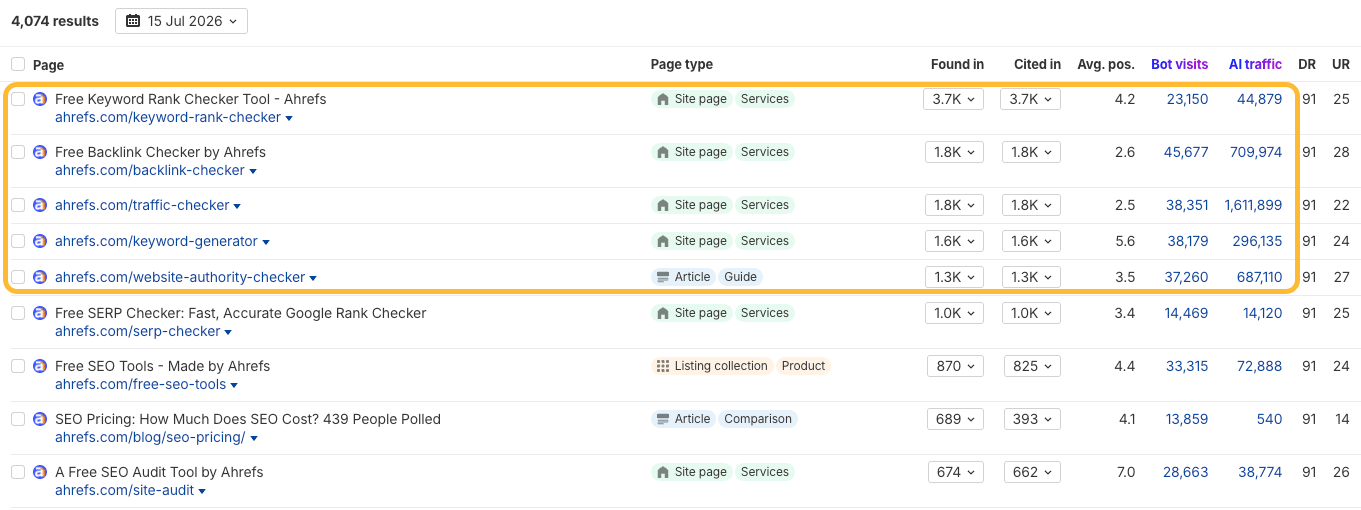
The same goes for online tools, calculators, and templates, and that’s our second category: content that resists AI summarization. AI can describe a backlink checker, but it can’t be one. That’s one reason many of these keywords don’t trigger AI Overviews.
At Ahrefs, these pages receive some of our highest levels of AI citations and traffic.
Recommendation
Content for AI search isn’t a separate investment.
The same content that earns AI citations—original research, firsthand experiments, unique perspectives, and exclusive data—is also the kind of content people share, journalists quote, podcasts discuss, and sales teams use.
It fuels your newsletter, gives you something worth posting on social media, supports sales conversations, and earns third-party mentions.
AI visibility is simply another benefit of creating content that’s worth publishing in the first place.
How to get started
Start with the citation gaps: topics where AI assistants cite your competitors but not you.
A citation gap is a demand signal. It tells you the topic already matters in your category—you just haven’t earned a place in the conversation yet.
Here’s how I’d find those gaps in Brand Radar. In the Overview report, open the Citations tab, hover over your brand, and click Others only.
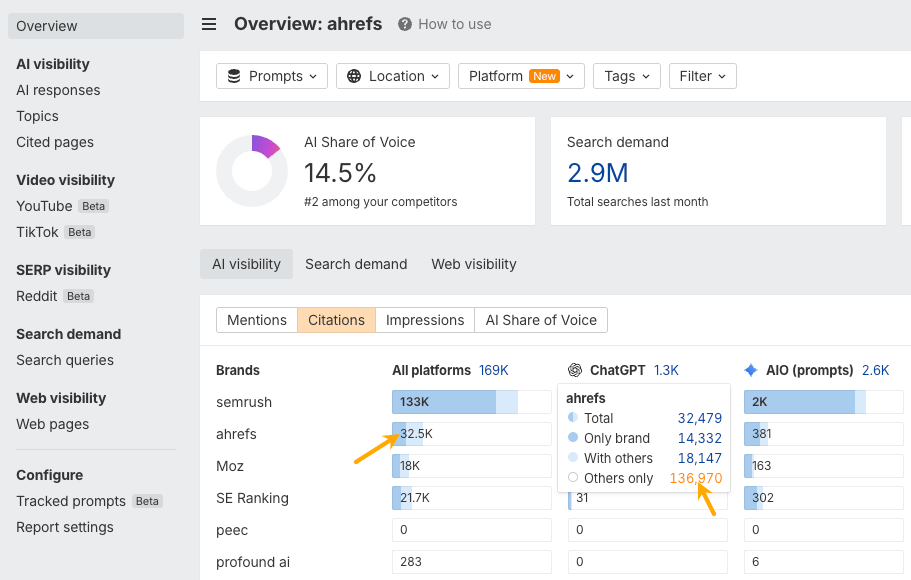
Next, open the Cited pages report. You’ll see pages AI already cites for those topics. Some may cover subjects you haven’t written about yet. Others may reveal pages on your site that could be improved.
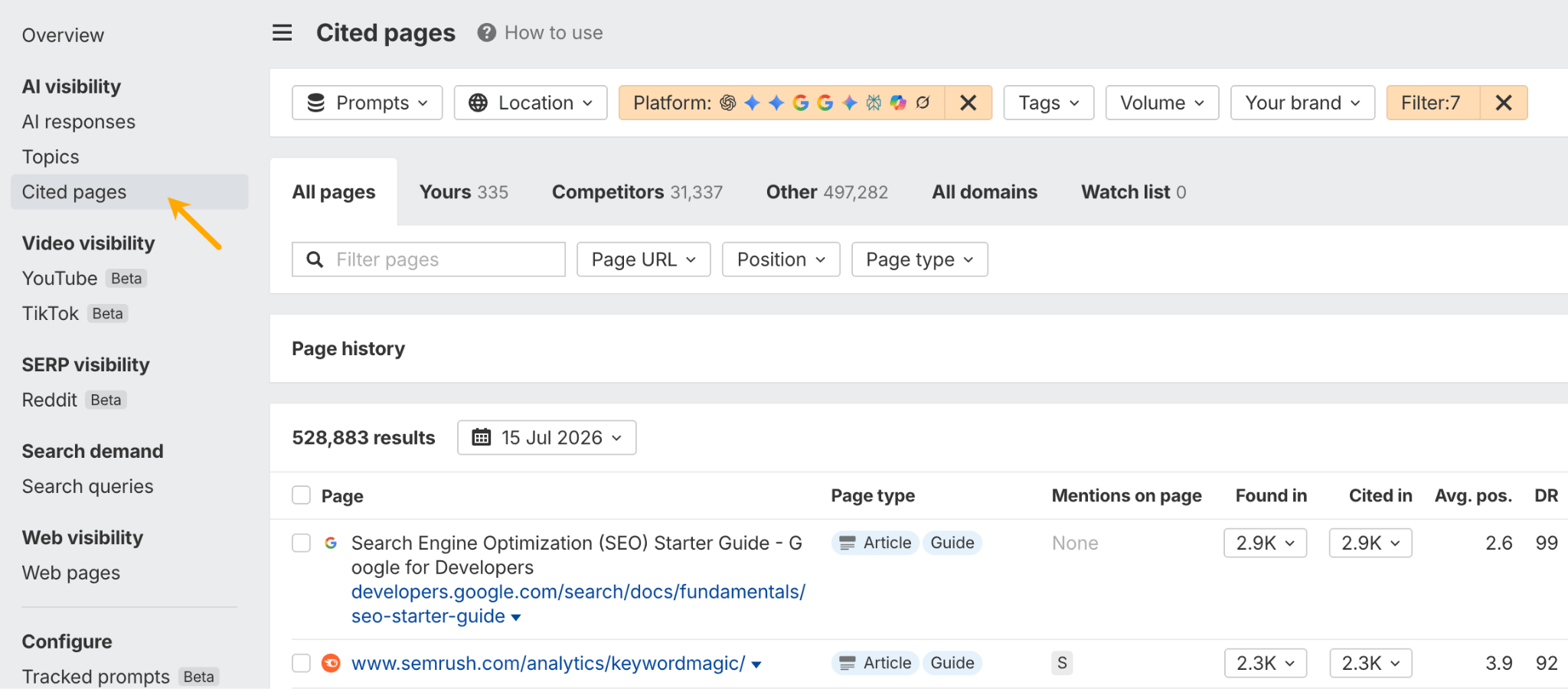
Use the Found in and Traffic columns to prioritize opportunities. Then check the Published column to see whether you can create something fresher than what’s already being cited.
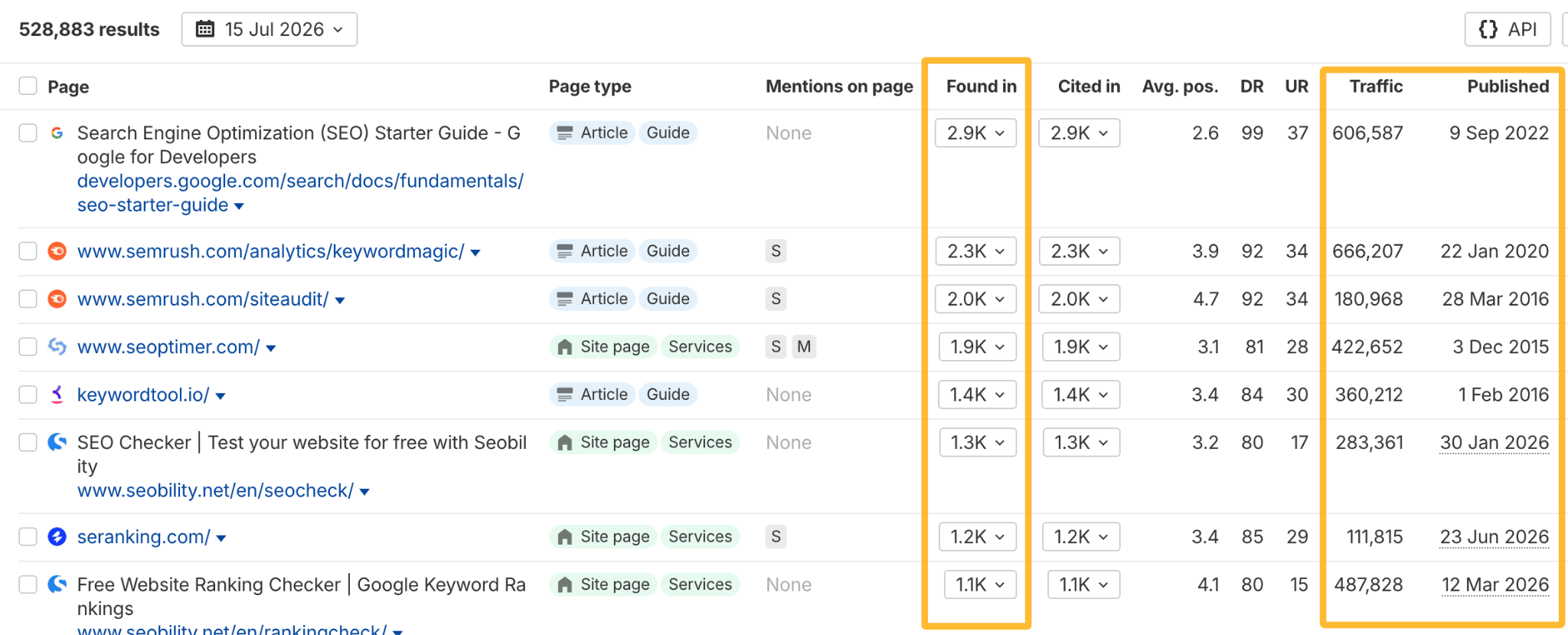
A useful trick is to filter the report to your closest competitors. If AI already cites them, there’s a good chance those are topics you should cover too.
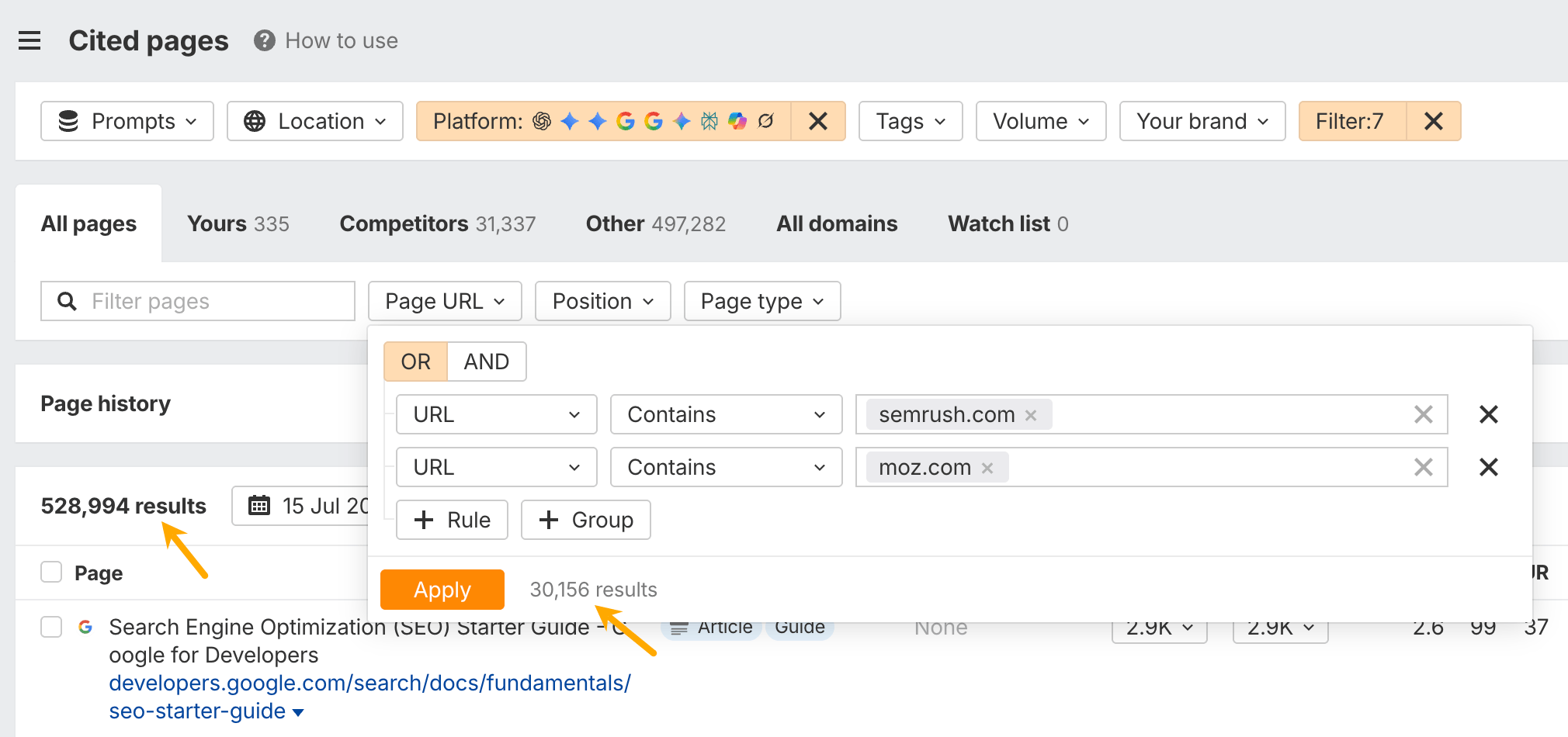
The final step is to ask what you can contribute that nobody else can.
Look for places where a citation gap overlaps with something unique to your business: internal data, customer research, benchmarks, experiments, or firsthand experience. That’s where you’ll create the strongest content.
For content that resists summarization—like free tools, calculators, and templates—you need a keyword research tool like Ahrefs’ Keywords Explorer to show you where Google doesn’t show AI Overviews yet. Enter keywords related to your business, open the Matching terms report, and filter out keywords that trigger AI Overviews.
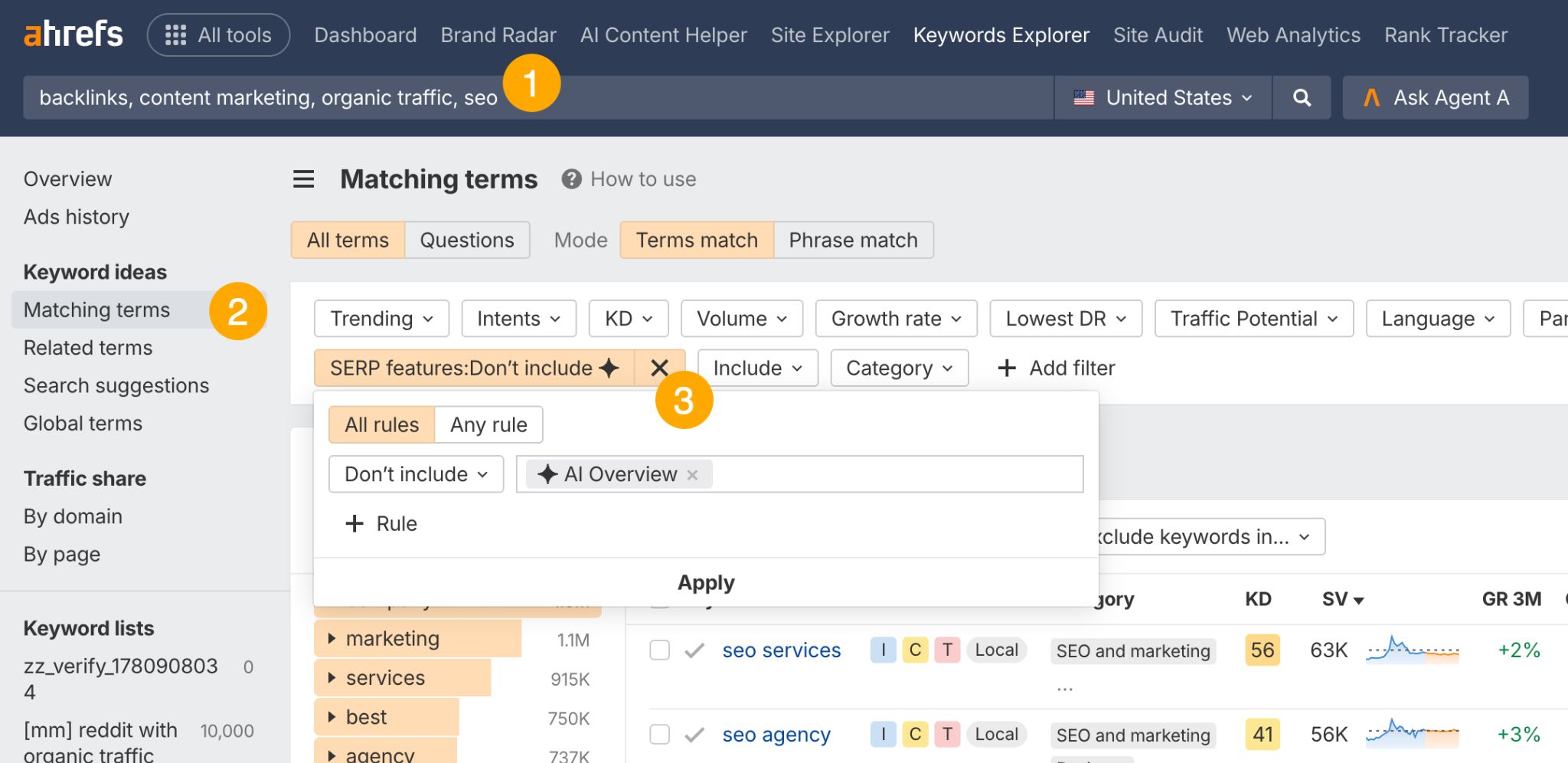
AI answers change quite often.
Between consecutive AI Overview responses for the same query, only 54% of named entities (specific things like brands, people, places) stay the same. On top of that, different assistants rely on different search indexes: ChatGPT uses Bing and Google, Gemini uses Google, Copilot uses Bing, Claude uses Brave, and Perplexity has its own.
That means your brand might appear in one assistant’s answer and disappear from another’s. For instance, Xbox is mentioned more often than PlayStation in ChatGPT, Perplexity, and Copilot, but PlayStation is more popular across the entire Google ecosystem:
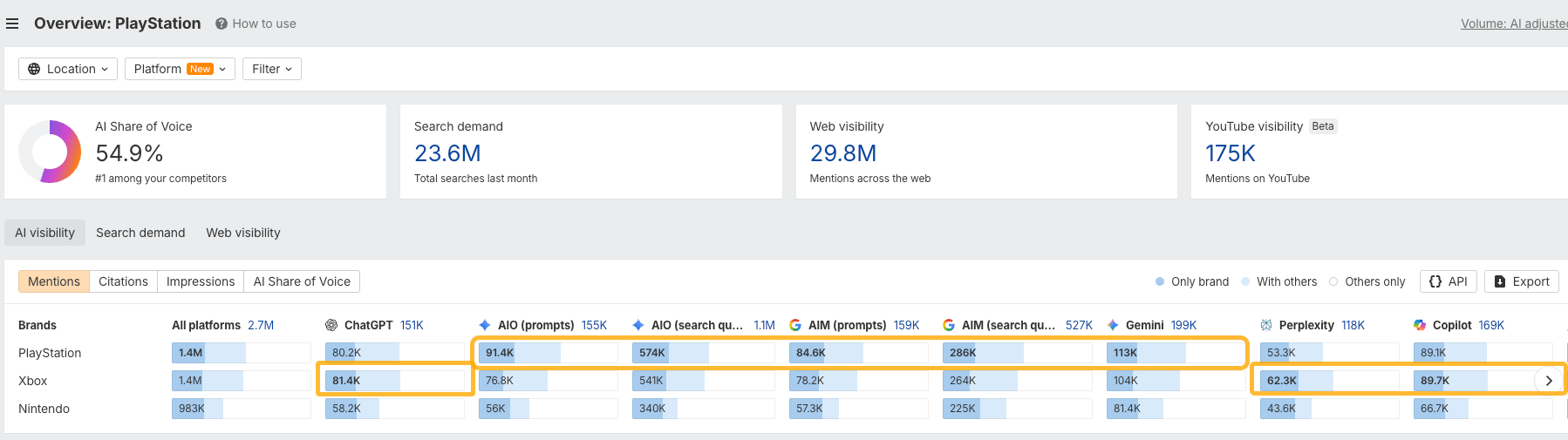
Instead of tracking individual responses, measure your visibility across many prompts and AI systems over time. Think of it more like a share of voice than search rankings.
What matters is your average presence across the questions, platforms, and buying scenarios your audience cares about.
How to get started
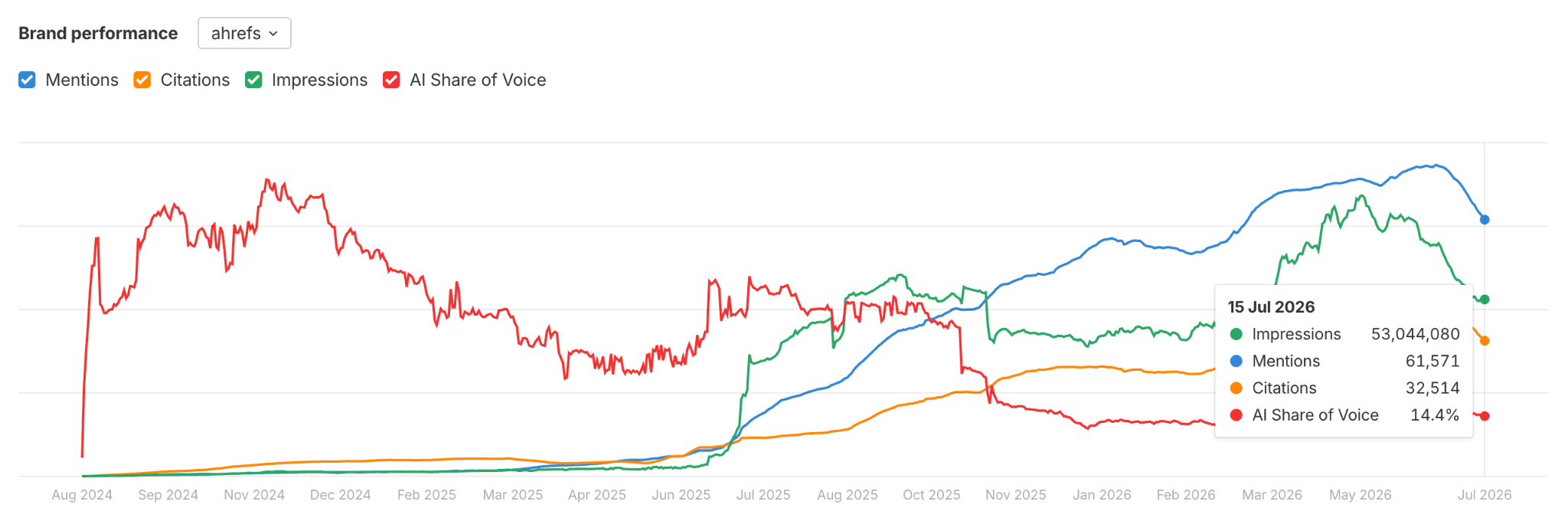
If you’re using Brand Radar, start by creating a report and adding your competitors. The Brand performance chart tracks your mentions, citations, AI share of voice, and estimated impressions over time, making it easy to see both your current performance and long-term trends.
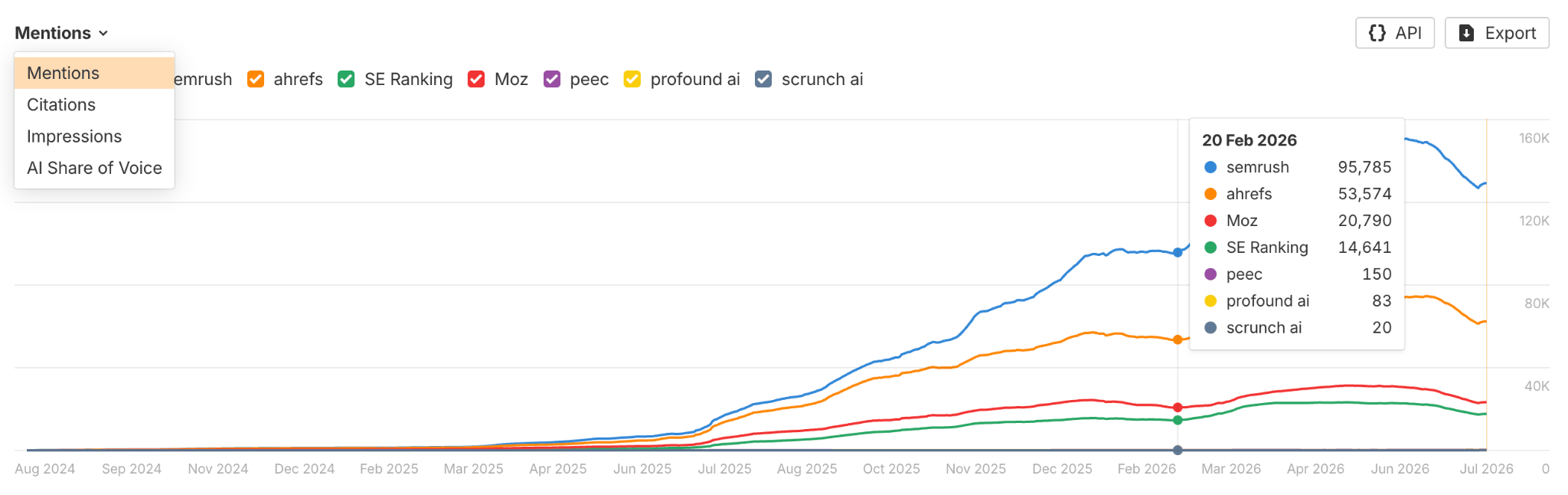
The chart above it lets you compare those same metrics across competitors. You can switch between AI visibility metrics using the selector in the top-left corner.
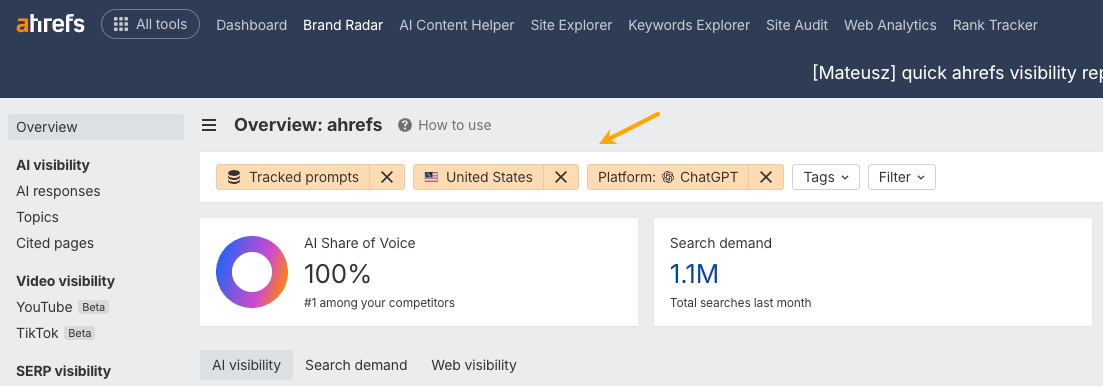
Use the upper filters to switch between prompt indexes, AI platform, and location.
Together, these reports answer four basic questions:
- How often is my brand mentioned?
- How often does AI cite my website?
- How many people are likely to see those mentions?
- How do I compare with my competitors?
That’s enough to establish a baseline and monitor your progress over time.
As you become more comfortable with these metrics, you can build a more specialized, custom dashboard. Here’s an example of one I’m building in Letaido for Letaido as a brand:
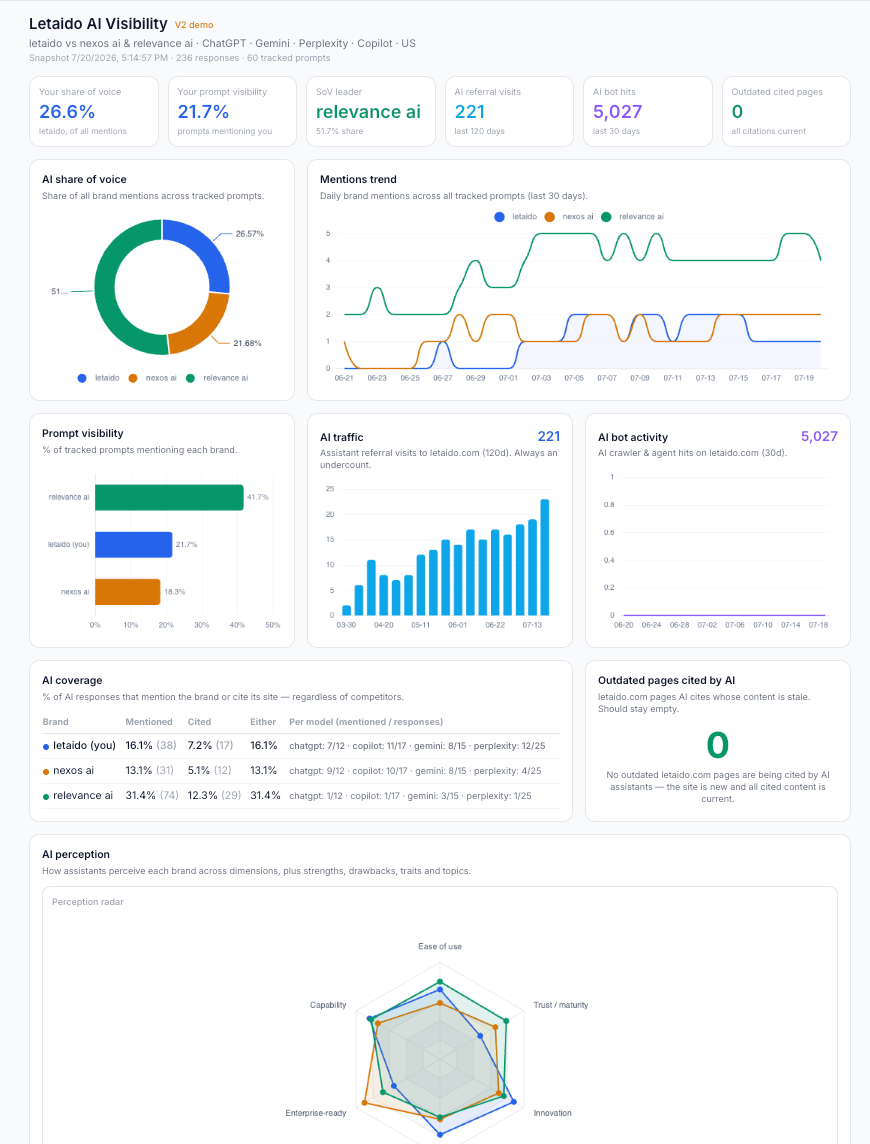
In addition to the core metrics, I track:
AI share of voice. The percentage of tracked prompts that mention your brand, compared against competitors. This is my quick-glance number for overall strategy. Coverage tells you how you’re doing in absolute terms; share of voice tells you whether you’re winning or losing the conversation.
AI traffic: Referral traffic from AI assistants. Helps to understand which content survives summarization and which pages people typically land after AI chats. I don’t treat it as the primary KPI: AI often influences journeys that analytics can’t fully attribute. Someone might discover your brand in ChatGPT, then return later through Google, a bookmark, or a direct visit.
AI bot activity. How often AI crawlers visit your site. Use this as a diagnostic metric. If new content isn’t being crawled, it’s unlikely to appear in AI answers. A sudden drop in crawler activity can also help explain why visibility isn’t improving as expected.
AI coverage. The percentage of tracked prompts that mention your brand or cite your website—split into mentions vs. citations, since being name-dropped and being linked are different wins.
If you publish original research, launch a PR campaign, or improve your documentation, coverage tells you whether those efforts actually increased your presence across the prompts that matter.
Also very useful for new brands and new niches, where it’s more important how often you show up at all, regardless of competitors.
AI perception. How AI consistently describes your business, scored across dimensions like ease of use, enterprise-readiness, and trust, alongside the adjectives, use cases, and strengths AI associates with the brand.
Over time, this reveals whether the market narrative is shifting in the direction you want, or whether AI has developed inaccurate or outdated associations that need to be corrected through better content or stronger third-party signals.
Outdated pages cited by AI. Pages AI assistants cite but whose content is stale: old pricing, deprecated features, pre-launch copy, etc. AI keeps quoting what it found, not what’s true today.
Recommendations. The “so what” layer. Prompts where competitors get cited and you don’t, topic segments where you’re absent entirely, and third-party pages that misrepresent your brand—each paired with a concrete action. Without this, an AI visibility dashboard is just monitoring; this is where it turns into a to-do list.
As AI search grows, it’s easy to chase shortcuts. Most of them don’t work for long.
Self-promotional “best tools” lists
Publishing an apparently objective comparison where your own product ranks first may earn citations, but it can also give your competitors more visibility.
In our experiment, self-promotional listicles sometimes became free marketing for the very brands they were trying to beat. AI used that content to generate answers, but often chose to feature some other brands we mentioned in the text instead of us—perfect irony.
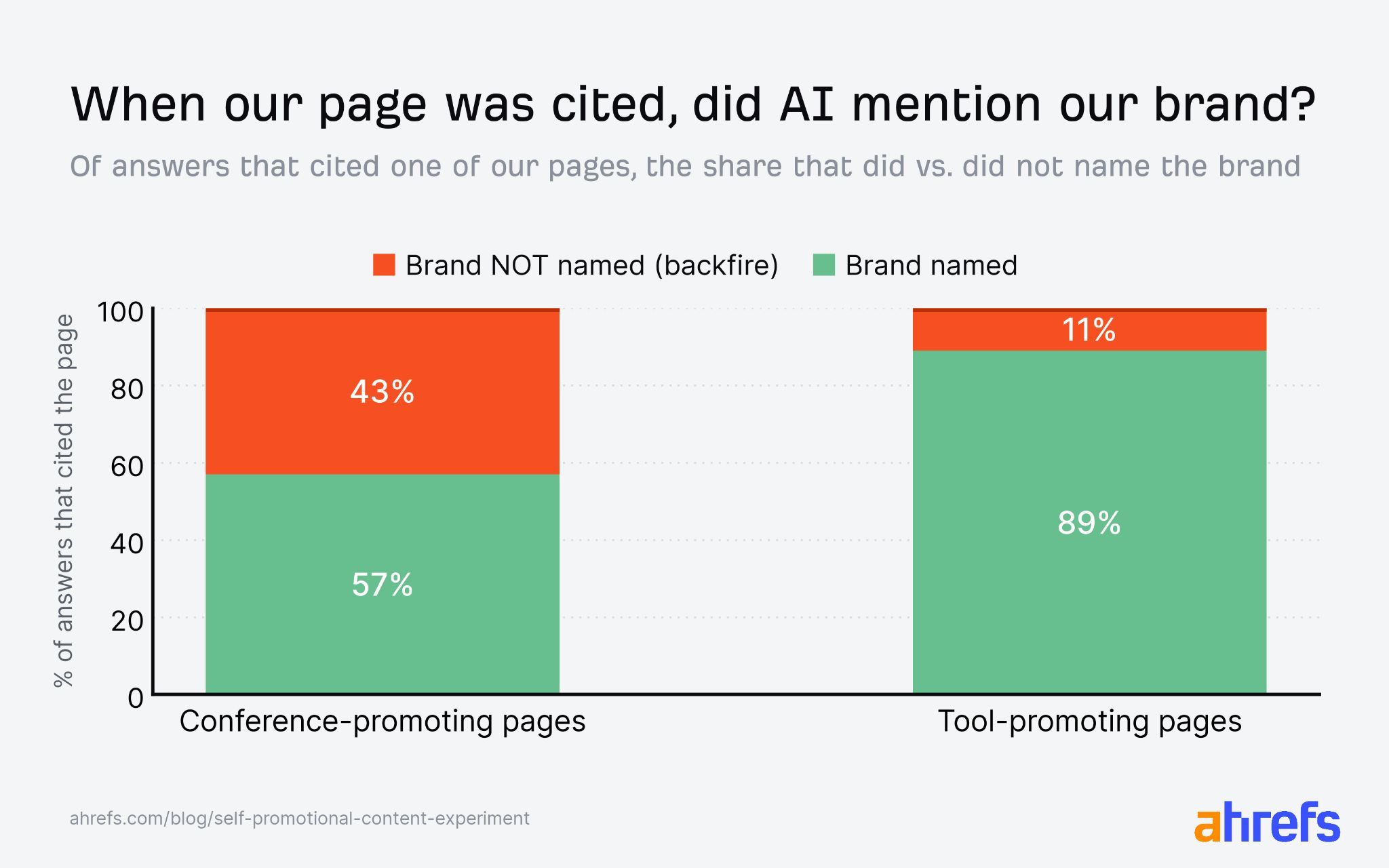
Product comparison pages can still work. Be transparent about your relationship to the products, explain who each tool is best for, and acknowledge where competitors are stronger. That makes the content more credible—for both readers and AI.
Large volumes of unreviewed AI-generated content (aka scaled content)
AI has made content cheaper to produce. It hasn’t made generic content more valuable.
Publishing hundreds of lightly reviewed pages often leads to repetitive content, weak research, and factual errors. It’s also one of the signals Google associates with scaled spam.
This often creates what’s become known as “Mount AI”: a rapid spike in organic traffic followed by an equally sharp decline.
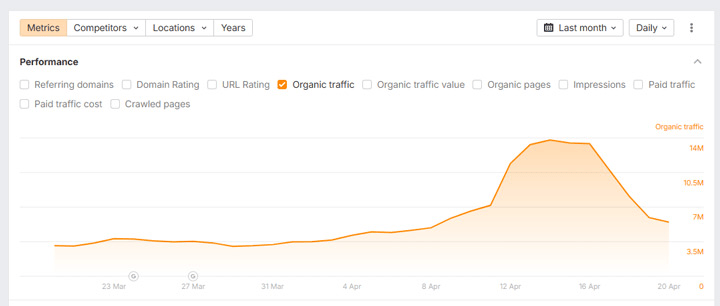
Glen Gabe and Lily Ray have documented several examples of AI-first content strategies that produced short-term gains before being hit by Google updates:
AI is great for research, analysis, outlining, and editing. It shouldn’t replace original ideas, firsthand experience, evidence, or human judgment.
Blocking AI crawlers (unless you have a really good reason)
Check your robots.txt file, firewall, and CDN settings for crawlers such as GPTBot, ClaudeBot, PerplexityBot, and Google-Extended.
There are valid reasons to block some of them, for example, publishers that license their content. Just make sure it’s a deliberate decision rather than an accidental configuration.
AI search feels like a new channel, but it rewards many of the same things that have always mattered: clear communication, credible third-party validation, original content, and consistent measurement.
What’s different is how those signals come together. Never before could a search experience tell someone so much about your brand in a matter of seconds. Instead of showing a list of links, AI synthesizes everything it knows—from your website and documentation to reviews, news articles, Reddit discussions, and YouTube videos—into a single answer.
That’s why AI search feels unfamiliar. It brings together channels that marketers have traditionally managed separately. SEO, content marketing, digital PR, brand marketing, product documentation, and customer advocacy all influence the same conversation.
Performance in AI search is no longer just an SEO problem. It’s the result of how well your entire marketing ecosystem helps AI understand, verify, and recommend your brand.
Thanks for reading! Come and say hi on LinkedIn or Substack.